

| << Chapter < Page | Chapter >> Page > |
When talking about linear regression, we discussed the problem of whether to fit a “simple” model such as the linear“ ,” or a more “complex” model such as the polynomial “ .” We saw the following example:
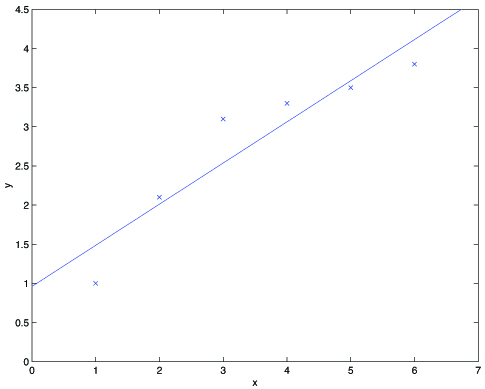
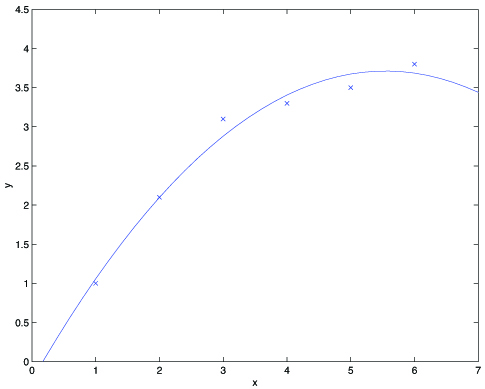
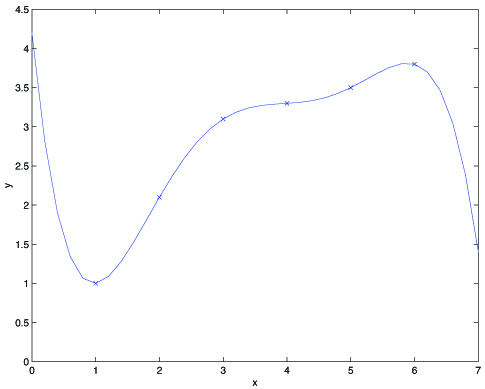
Fitting a 5th order polynomial to the data (rightmost figure) did not result in a good model. Specifically, even though the 5th order polynomial did a very good jobpredicting (say, prices of houses) from (say, living area) for the examples in the training set, we do not expect the model shown to be a good one for predictingthe prices of houses not in the training set. In other words, what's has been learned from the training set does not generalize well to other houses. The generalization error (which will be made formal shortly) of a hypothesis is its expected error on examples not necessarily in thetraining set.
Both the models in the leftmost and the rightmost figures above have large generalization error. However, the problems that the two models suffer fromare very different. If the relationship between and is not linear, then even if we were fitting a linear model to a very large amount of trainingdata, the linear model would still fail to accurately capture the structure in the data. Informally, we define the bias of a model to be the expected generalization error even if we were to fit it to a very (say,infinitely) large training set. Thus, for the problem above, the linear model suffers from large bias, and may underfit (i.e., fail to capturestructure exhibited by) the data.
Apart from bias, there's a second component to the generalization error, consisting of the variance of a model fitting procedure. Specifically, when fitting a 5th order polynomial as in the rightmost figure, there is alarge risk that we're fitting patterns in the data that happened to be present in our small, finite training set, but that do not reflect thewider pattern of the relationship between and . This could be, say, because in thetraining set we just happened by chance to get a slightly more-expensive-than-average house here, and a slightly less-expensive-than-average house there, and so on.By fitting these “spurious” patterns in the training set, we might again obtain a model with large generalization error. In this case, we say themodel has large variance. In these notes, we will not try to formalize the definitions of bias and variance beyond this discussion.While bias and variance are straightforward to define formally for, e.g., linear regression,there have been several proposals for the definitions of bias and variance for classification, and there is as yet no agreement on what isthe “right” and/or the most useful formalism.
Often, there is a tradeoff between bias and variance. If our model is too “simple” and has very few parameters, then it may have largebias (but small variance); if it is too “complex” and has very many parameters, then it may suffer from large variance (but have smaller bias). In the example above, fitting a quadratic function does better than either of the extremes of a firstor a fifth order polynomial.
Notification Switch
Would you like to follow the 'Machine learning' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|