

| << Chapter < Page | Chapter >> Page > |
Let's put all this together into a theorem.
Theorem. Let , and let any be fixed. Then with probability at least , we have that
This is proved by letting equal the term, using our previous argument that uniform convergence occurs with probability at least , and then noting that uniform convergence implies is at most higher than (as we showed previously).
This also quantifies what we were saying previously saying about the bias/variance tradeoff in model selection. Specifically, suppose we have some hypothesis class , and are considering switching to some much larger hypothesis class . If we switch to , then the first term can only decrease (since we'd then be taking a min over a larger set of functions). Hence,by learning using a larger hypothesis class, our “bias” can only decrease. However, if k increases, then the second term would also increase. This increase corresponds to our “variance” increasingwhen we use a larger hypothesis class.
By holding and fixed and solving for like we did before, we can also obtain the following sample complexity bound:
Corollary. Let , and let any be fixed. Then for to hold with probability at least , it suffices that
We have proved some useful theorems for the case of finite hypothesis classes. But many hypothesis classes, including any parameterized by real numbers(as in linear classification) actually contain an infinite number of functions. Can we prove similar results for this setting?
Let's start by going through something that is not the “right” argument. Better and more general arguments exist , but this will be useful for honing our intuitions about the domain.
Suppose we have an
that is parameterized by
real numbers. Since we are using a computer to
represent real numbers, and IEEE double-precision floating point (
double 's in C)
uses 64 bitsto represent a floating point number, this means that our learning algorithm, assuming we're using
double-precision floating point, is parameterized by
bits. Thus, our hypothesis class
really consists of at most
different hypotheses. From the Corollary at the end of the
previous section, we therefore find that, to guarantee
, with to hold with probability at least
,
it suffices that
. (The
subscripts are to indicate that the last big-
is hiding constants that may
depend on
and
.) Thus, the number of training examples needed is at most
linear in the parameters of the model.
The fact that we relied on 64-bit floating point makes this argument not entirely satisfying, but the conclusion is nonetheless roughly correct: If what we're going to do is try to minimize training error,then in order to learn “well” using a hypothesis class that has parameters, generally we're going to need on the order of a linear number of training examples in .
(At this point, it's worth noting that these results were proved for an algorithm that uses empirical risk minimization. Thus, while the linear dependence of samplecomplexity on does generally hold for most discriminative learning algorithms that try to minimize trainingerror or some approximation to training error, these conclusions do not always apply as readily to discriminative learning algorithms. Giving good theoreticalguarantees on many non-ERM learning algorithms is still an area of active research.)
The other part of our previous argument that's slightly unsatisfying is that it relies on the parameterization of . Intuitively, this doesn't seem like it should matter: We had written the classof linear classifiers as , with parameters . But it could also be written with parameters . Yet, both of these are just defining the same : The set of linear classifiers in dimensions.
To derive a more satisfying argument, let's define a few more things.
Given a set (no relation to the training set) of points , we say that shatters if can realize any labeling on . I.e., if for any set of labels , there existssome so that for all .
Given a hypothesis class , we then define its Vapnik-Chervonenkis dimension , written , to be the size of the largest set that is shattered by . (If can shatter arbitrarily large sets, then .)
For instance, consider the following set of three points:
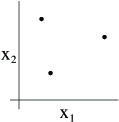
Can the set of linear classifiers in two dimensions ( ) can shatter the set above? The answer is yes. Specifically, we see that, for any of the eight possiblelabelings of these points, we can find a linear classifier that obtains “zero training error” on them:
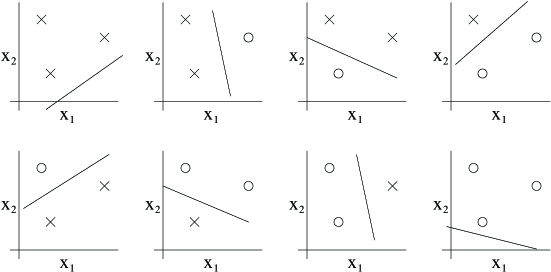
Moreover, it is possible to show that there is no set of 4 points that this hypothesis class can shatter. Thus, the largest set that can shatter is of size 3, and hence .
Note that the VC dimension of here is 3 even though there may be sets of size 3 that it cannot shatter. For instance, if we had a set of three pointslying in a straight line (left figure), then there is no way to find a linear separator for the labeling of the three points shown below (right figure):
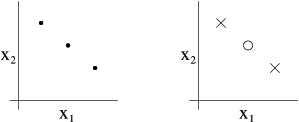
In order words, under the definition of the VC dimension, in order to prove that is at least , we need to show only that there's at least one set of size that can shatter.
The following theorem, due to Vapnik, can then be shown. (This is, many would argue, the most important theorem in all of learning theory.)
Theorem. Let be given, and let . Then with probability at least , we have that for all ,
Thus, with probability at least , we also have that:
In other words, if a hypothesis class has finite VC dimension, then uniform convergence occurs as becomes large. As before,this allows us to give a bound on in terms of . We also have the following corollary:
Corollary. For to hold for all (and hence ) with probability at least , it suffices that .
In other words, the number of training examples needed to learn “well” using is linear in the VC dimension of . It turns out that, for “most” hypothesis classes, the VC dimension (assuming a “reasonable” parameterization) is also roughly linear in the number of parameters.Putting these together, we conclude that (for an algorithm that tries to minimize training error) the number of trainingexamples needed is usually roughly linear in the number of parameters of .
Notification Switch
Would you like to follow the 'Machine learning' conversation and receive update notifications?

|
|

|
|

|
|
|
|
|

|
|

|
|

|
|
|
|
|

|
|
|
|