

| << Chapter < Page | Chapter >> Page > |
In the equation above, “ ” denotes the determinant of the matrix .
For a random variable distributed , the mean is (unsurprisingly) given by :
The covariance of a vector-valued random variable is defined as . This generalizes the notion of the variance of a real-valued random variable. The covariance canalso be defined as . (You should be able to prove to yourself that these two definitions are equivalent.)If , then
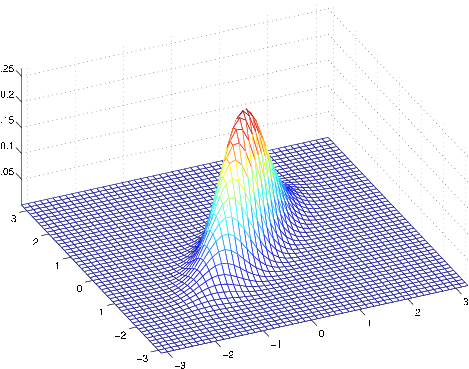
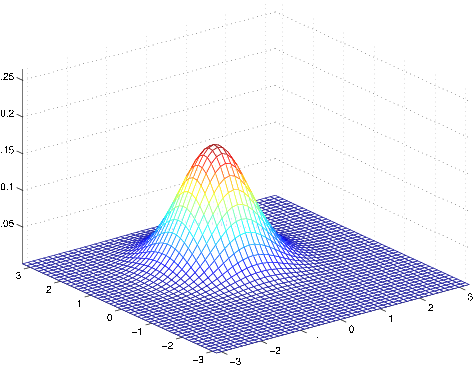
Here're some examples of what the density of a Gaussian distribution looks like:
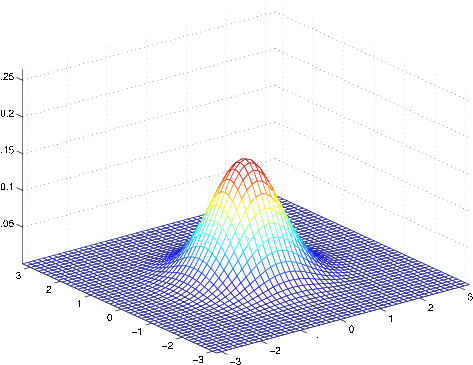
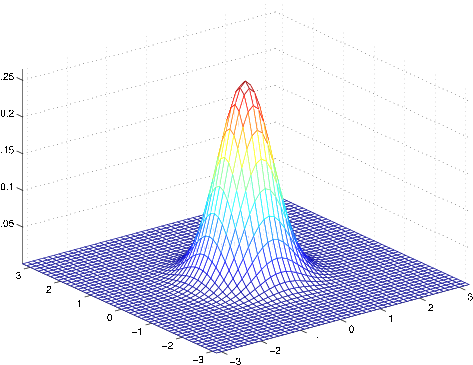

The left-most figure shows a Gaussian with mean zero (that is, the 2x1 zero-vector) and covariance matrix (the 2x2 identity matrix). A Gaussian with zero mean and identity covariance is also called the standard normal distribution . The middle figure shows the density of a Gaussian with zero mean and ; and in the rightmost figure shows one with , . We see that as becomes larger, the Gaussian becomes more “spread-out,” and as it becomes smaller, the distribution becomesmore “compressed.”
Let's look at some more examples.
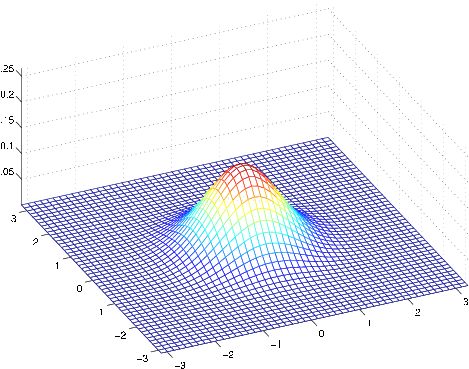
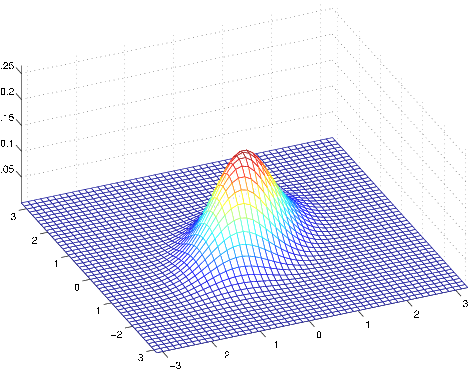
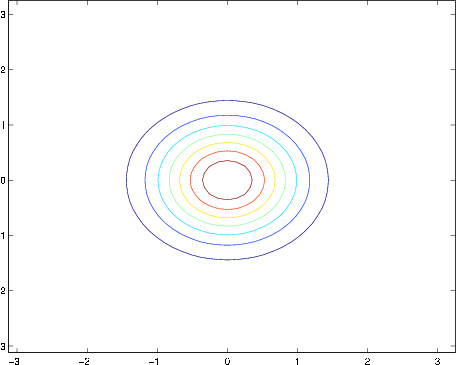
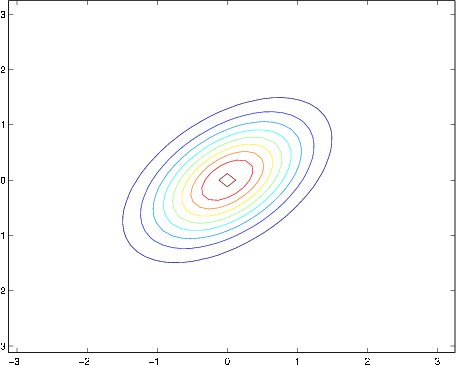
The figures above show Gaussians with mean 0, and with covariance matrices respectively
The leftmost figure shows the familiar standard normal distribution, and we see that as we increase the off-diagonal entry in , the density becomes more “compressed” towards the line (given by ). We can see this more clearly when we look at the contours of the same three densities:
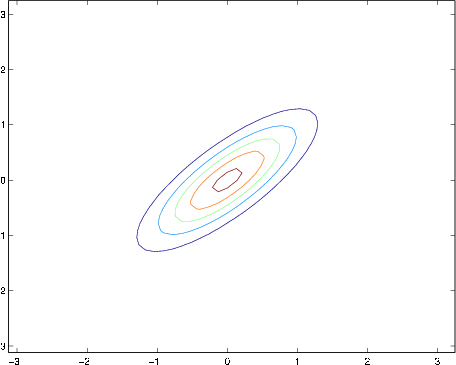
Here's one last set of examples generated by varying :
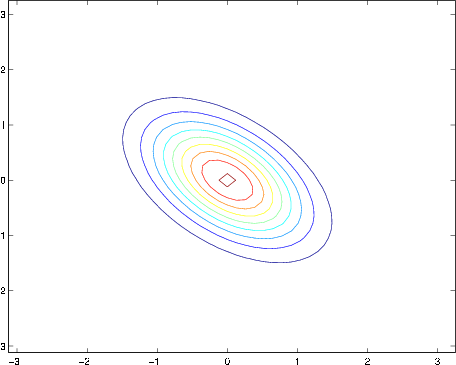
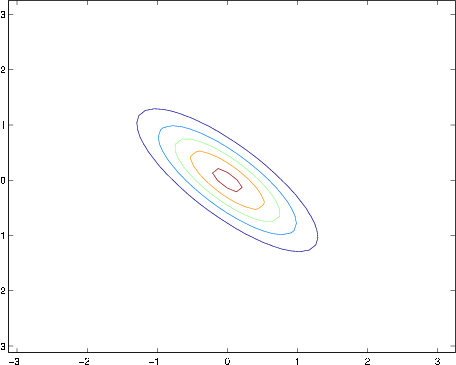
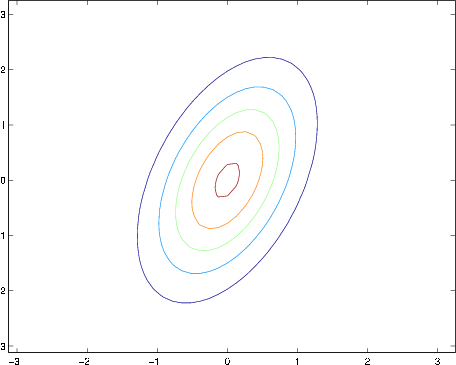
The plots above used, respectively,
From the leftmost and middle figures, we see that by decreasing the diagonal elements of the covariance matrix, the density now becomes “compressed” again, but in the opposite direction.Lastly, as we vary the parameters, more generally the contours will form ellipses (the rightmost figure showing an example).
As our last set of examples, fixing , by varying , we can also move the mean of the density around.
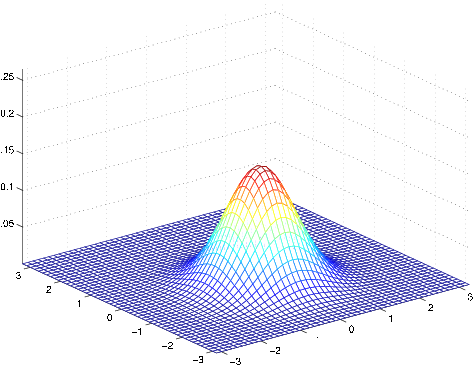

The figures above were generated using , and respectively
When we have a classification problem in which the input features are continuous-valued random variables, we can then use the Gaussian Discriminant Analysis (GDA) model, whichmodels using a multivariate normal distribution. The model is:
Writing out the distributions, this is:
Here, the parameters of our model are , , and . (Note that while there're two different mean vectors and , this model is usually applied using only one covariance matrix .) The log-likelihood of the data is given by
By maximizing with respect to the parameters, we find the maximum likelihood estimate of the parameters (see problem set 1) to be:
Notification Switch
Would you like to follow the 'Machine learning' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|