

| << Chapter < Page | Chapter >> Page > |
Moreover, if some satisfy the KKT conditions, then it is also a solution to the primal and dual problems.
We draw attention to the third equation in [link] , which is called the KKT dual complementarity condition. Specifically, it implies that if , then . (I.e., the “ ” constraint is active , meaning it holds with equality rather than with inequality.)Later on, this will be key for showing that the SVM has only a small number of “support vectors”; the KKT dual complementarity condition will also give us our convergence test when we talkabout the SMO algorithm.
Previously, we posed the following (primal) optimization problem for finding the optimal margin classifier:
We can write the constraints as
We have one such constraint for each training example. Note that from the KKT dualcomplementarity condition, we will have only for the training examples that have functional margin exactly equal to one (i.e., the ones correspondingto constraints that hold with equality, ). Consider the figure below, in which a maximum margin separating hyperplane is shown by the solid line.
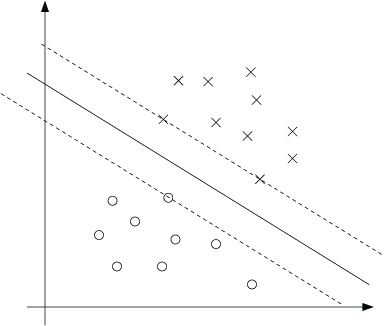
The points with the smallest margins are exactly the ones closest to the decision boundary; here, these are the three points (one negative and two positive examples)that lie on the dashed lines parallel to the decision boundary. Thus, only three of the 's—namely, the ones corresponding to these three training examples—will be non-zero at the optimal solution to our optimization problem. These three pointsare called the support vectors in this problem. The fact that the number of support vectors can be much smaller than the size the training set will be useful later.
Let's move on. Looking ahead, as we develop the dual form of the problem, one key idea to watch out for is that we'll try to write our algorithm in terms of only the inner product (think of this as ) between points in the input feature space. The fact that we can express our algorithm interms of these inner products will be key when we apply the kernel trick.
When we construct the Lagrangian for our optimization problem we have:
Note that there're only “ ” but no “ ” Lagrange multipliers, since the problem has only inequality constraints.
Let's find the dual form of the problem. To do so, we need to first minimize with respect to and (for fixed ), to get , which we'll do by setting the derivatives of with respect to and to zero. We have:
This implies that
As for the derivative with respect to , we obtain
If we take the definition of in Equation [link] and plug that back into the Lagrangian (Equation [link] ), and simplify, we get
Notification Switch
Would you like to follow the 'Machine learning' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|