

| << Chapter < Page | Chapter >> Page > |
The
C$OMP is the sentinel that indicates that this is a directive and not just another comment. The output of the program when run looks as follows:
% setenv OMP_NUM_THREADS 4% a.out
Hello ThereI am 0 of 4
I am 3 of 4I am 1 of 4
I am 2 of 4All Done
%
Execution begins with a single thread. As the program encounters the
PARALLEL directive, the other threads are activated to join the computation. So in a sense, as execution passes the first directive, one thread becomes four. Four threads execute the two statements between the directives. As the threads are executing independently, the order in which the print statements are displayed is somewhat random. The threads wait at the
END PARALLEL directive until all threads have arrived. Once all threads have completed the parallel region, a single thread continues executing the remainder of the program.
In
[link] , the
PRIVATE(IAM) indicates that the
IAM variable is not shared across all the threads but instead, each thread has its own private version of the variable. The
IGLOB variable is shared across all the threads. Any modification of
IGLOB appears in all the other threads instantly, within the limitations of the cache coherency.
Data interactions during a parallel region
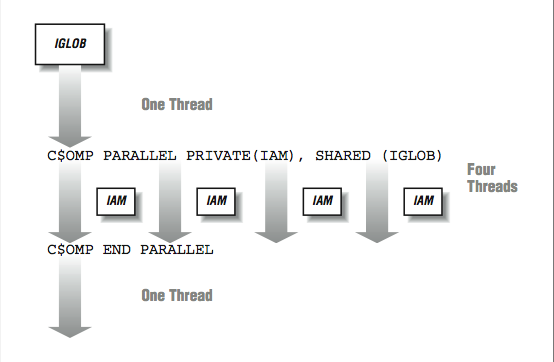
During the parallel region, the programmer typically divides the work among the threads. This pattern of going from single-threaded to multithreaded execution may be repeated many times throughout the execution of an application.
Because input and output are generally not thread-safe, to be completely correct, we should indicate that the print statement in the parallel section is only to be executed on one processor at any one time. We use a directive to indicate that this section of code is a critical section. A lock or other synchronization mechanism ensures that no more than one processor is executing the statements in the critical section at any one time:
C$OMP CRITICAL
PRINT *, ’I am ’, IAM, ’ of ’, IGLOBC$OMP END CRITICAL
Quite often the areas of the code that are most valuable to execute in parallel are loops. Consider the following loop:
DO I=1,1000000
TMP1 = ( A(I) ** 2 ) + ( B(I) ** 2 )TMP2 = SQRT(TMP1)
B(I) = TMP2ENDDO
To manually parallelize this loop, we insert a directive at the beginning of the loop:
C$OMP PARALLEL DO
DO I=1,1000000TMP1 = ( A(I) ** 2 ) + ( B(I) ** 2 )
TMP2 = SQRT(TMP1)B(I) = TMP2
ENDDOC$OMP END PARALLEL DO
When this statement is encountered at runtime, the single thread again summons the other threads to join the computation. However, before the threads can start working on the loop, there are a few details that must be handled. The
PARALLEL DO directive accepts the data classification and scoping clauses as in the parallel section directive earlier. We must indicate which variables are shared across all threads and which variables have a separate copy in each thread. It would be a disaster to have
TMP1 and
TMP2 shared across threads. As one thread takes the square root of
TMP1 , another thread would be resetting the contents of
TMP1 .
A(I) and
B(I) come from outside the loop, so they must be shared. We need to augment the directive as follows:
Notification Switch
Would you like to follow the 'High performance computing' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|
|
|
|

|
|

|