

| << Chapter < Page | Chapter >> Page > |
In our discussion of factor analysis, we gave a way to model data as “approximately” lying in some -dimension subspace, where . Specifically, we imagined that each point was created by first generating some lying in the -dimension affine space , and then adding -covariance noise. Factor analysis is based on a probabilistic model, and parameter estimationused the iterative EM algorithm.
In this set of notes, we will develop a method, Principal Components Analysis (PCA),
that also tries to identify the subspace in which the data approximately lies.However, PCA will do so more directly, and will require only an eigenvector
calculation (easily done with the
eig function
in Matlab), and does not need to resort to EM.
Suppose we are given a dataset of attributes of different types of automobiles, such as their maximum speed, turn radius, and so on. Let for each ( ). But unknown to us, two different attributes—some and —respectively give a car's maximum speed measured in miles per hour, and the maximum speed measured in kilometers per hour.These two attributes are therefore almost linearly dependent, up to only small differences introduced by rounding off to the nearest mph or kph. Thus, the data really lies approximatelyon an dimensional subspace. How can we automatically detect, and perhaps remove, this redundancy?
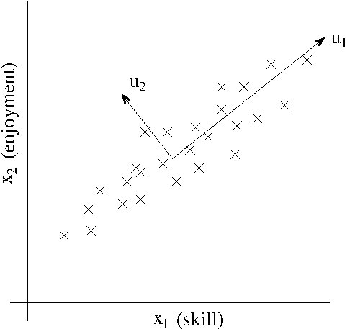
For a less contrived example, consider a dataset resulting from a survey of pilots for radio-controlled helicopters,where is a measure of the piloting skill of pilot , and captures how much he/she enjoys flying. Because RC helicopters are very difficult to fly,only the most committed students, ones that truly enjoy flying, become good pilots. So, the two attributes and are strongly correlated. Indeed, we might posit that that the data actually likes along some diagonalaxis (the direction) capturing the intrinsic piloting “karma” of a person, with only a small amount of noise lying off this axis. (See figure.) How can we automatically compute this direction?
We will shortly develop the PCA algorithm. But prior to running PCA per se, typically we first pre-processthe data to normalize its mean and variance, as follows:
Steps (1-2) zero out the mean of the data, and may be omitted for data known to have zero mean (for instance, time series corresponding to speech or other acoustic signals).Steps (3-4) rescale each coordinate to have unit variance, which ensures that different attributesare all treated on the same “scale.” For instance, if was cars' maximum speed in mph (taking values in the high tens or low hundreds) and were the number of seats (taking values around 2-4), then this renormalization rescales the different attributes to make themmore comparable. Steps (3-4) may be omitted if we had apriori knowledge that the different attributes are all on the same scale. One example of this is if each data point represented agrayscale image, and each took a value in corresponding to the intensity value of pixel in image .
Notification Switch
Would you like to follow the 'Machine learning' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|
|

|