

| << Chapter < Page | Chapter >> Page > |
Considere lo que sucede cuando una línea de cache se rellena desde la memoria: se leen localidades de memoria consecutivas desde la memoria principal, para llenar con ellas localidades consecutivas en la línea de cache. El número de bytes transferidos dependen de cuan grande es la línea -cualquier cosa entre 16 bytes y 256 bytes o más. Queremos que esta operación de relleno se lleve a cabo rápidamente porque hay una instrucción atorada en la pipeline, o tal vez el procesador está esperando más instrucciones. En [link] , si tenemos dos chips DRAM que nos proporcionan 4 bits de datos cada 100 ns (recuerde el tiempo de ciclo), llenar una línea de cache de 16 bytes toma 1600 ns.
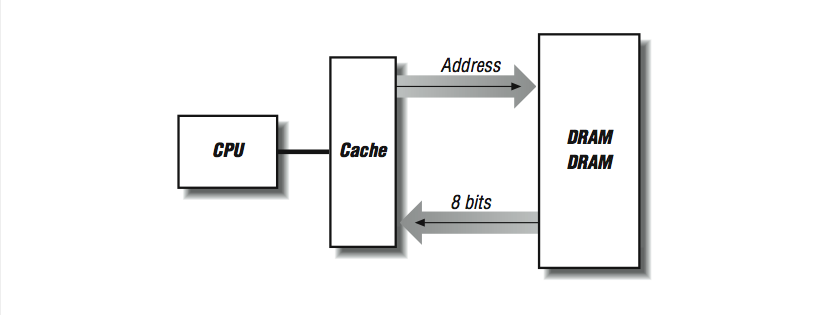
Una forma de acelerar la operación de llenado de la línea de cache consiste en "ensanchar" el sistema de memoria, como se muestra en [link] . En vez de tener dos renglones de DRAMs, creamos múltiples renglones. Ahora en cada ciclo de 100 ns obtenemos 32 bits contiguos, y nuestra línea de cache se llena cuatro veces más rápido.
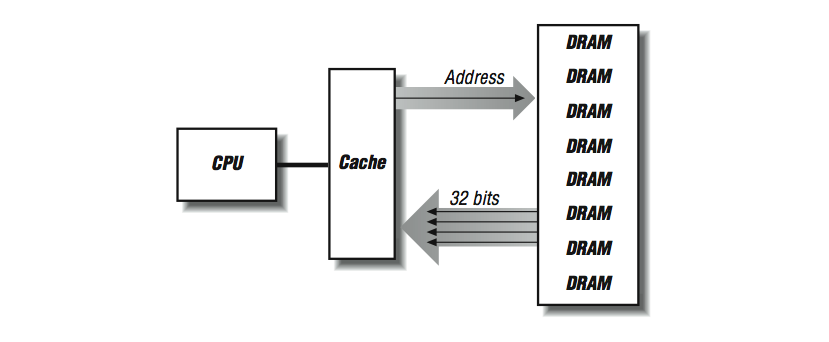
Podemos mejorar el rendimiento de un sistema de memoria, incrementando el ancho del mismo hasta que iguale la longitud de la línea de cache, momento en que podemos llenar la línea completa en un solo ciclo de memoria. En la serie de sistemas SGI Power Challenge el ancho de memoria es de 256 bits. El lado negativo de un sistema de memoria más ancho es que debe agregarse la DRAM en múltiplos enteros. En muchas estaciones de trabajo y computadoras personales modernas, la memoria se expande mediante módulos de memoria de una sola línea (SIMM por sus siglas en inglés), y dichos SIMMs son actualmente de 30, 72 o 168 patillas, cada uno de los cuales está hecho de varios chips DRAM listos para ser instalados en un subsistema de memoria.
Es interesante resaltar que casi hemos ocupado un capítulo completo a explicar lo buena que es la cache para las computadoras de alto rendimiento, y ahora vamos a evitar la cache para mejorar el rendimiento. Como se mencionó con anterioridad, algunos tipos de procesamiento resultan en incrementos no unitarios (o rebotes) a lo largo de la memoria. Estos tipos de patrones de referencia a memoria presentan el peor caso posible de comportamiento en arquitecturas basadas en cache. Este tipo de patrones de referencias es el que ve mejorado su rendimiento evitando la cache. La imposibilidad de soportar este tipo de computación continúa siendo un área donde las supercomputadoras tradicionales pueden comportarse peor que los procesadores RISC de alta velocidad. Por esta razón, los procesadores RISC que abordan seriamente el procesamiento numérico suelen tener instrucciones especiales que evitan el uso de la memoria cache; los datos se transfieren directamente entre el procesador y el sistema de memoria principal. por cierto, muchas máquinas tienen espacios de memoria sin cache para sincronización de procesos y registros de E/S. Sin embargo, las referencias a memoria en tales localidades evitan la cache por causa de la dirección elegida, no necesariamente por la instrucción elegida. En [link] tenemos cuatro bancos de SIMMs que pueden llenar la memoria cache a razón de 128 bits por cada ciclo de memoria de 100 ns. Recuerde que los datos están disponibles tras 50 ns, pero no podemos obtener más datos hasta que la DRAM se refresque, de 50 a 60 ns después. Sin embargo, si estamos realizando cargas de 32 bits en incrementos no unitarios y tenemos la capacidad de evitar la cache, cada carga quedará satisfecha desde alguno de los cuatro SIMMs en 50 ns. Mientras ese SIMM se refresca, puede ocurrir otra carga desde cualesquiera de los otros tres SIMMs en 50 ns. En una mezcla aleatoria de cargas no unitarias hay una probabilidad del 75% de que la siguiente carga caiga en una DRAM "fresca". Si la carga recae en un banco mientras se está refrescando, simplemente tiene que esperar hasta que se complete el refresco.
Notification Switch
Would you like to follow the 'Cómputo de alto rendimiento' conversation and receive update notifications?

|
|

|
|
|
|
|

|
|
|
|
|

|
|

|
|

|
|

|
|

|