Motivated by the cascade of memoryless quantization and entropy coding, the entropy-minimizing scalar memoryless quantizer is derived. Using a compander formulation and tools from the calculus of variations, it is shown that the entropy-minimizing quantizer is the simple uniform quantizer. The penalty associated with memoryless quantization is then analyzed in the asymptotic case of many quantization levels.
Say that we are designing a system with a memoryless quantizer
followed by an entropy coder, and our goal is to minimize theaverage transmission rate for a given
σ
q2 (or vice versa).
Is it optimal to cascade a
σ
q2 -minimizing (Lloyd-Max)
quantizer with a rate-minimizing code?In other words, what is the optimal memoryless quantizer if
the quantized outputs are to be entropy coded?
A Compander Formulation: To determine the optimal quantizer,
consider a
companding system: a memoryless nonlinearity
followed by uniform quantizer,
find
minimizing entropy
H
y for a fixed
error variance
σ
q2 .
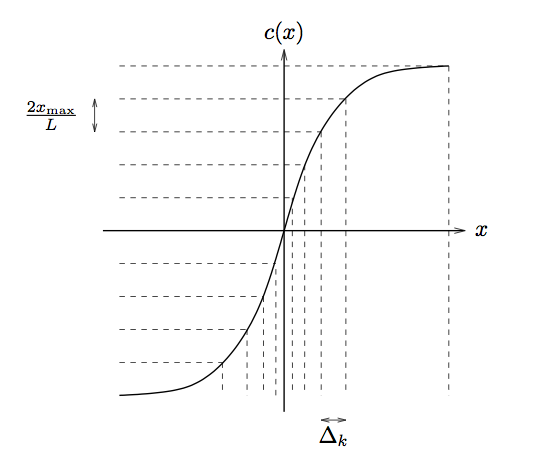
Compander curve: nonuniform input regions mapped to uniform output regions (for subsequent uniform quantization)
First we must express
σ
q2 and
H
y in terms of
.
[link] suggests that, for large
L , the slope
obeys
Entropy-Minimizing Quantizer: Our goal is to choose
which minimizes the entropy rate
H
y subject to fixed error variance
σ
q2 .
We employ a Lagrange technique again, minimizingthe cost
under the constraint that the quantity
equals a constant
C .
This yields the unconstrained cost function
with scalar
λ , and the unconstrained optimization problem becomes
The following technique is common in variational calculus (see, e.g., Optimal Systems Control by Sage&White).
Say
minimizes a (scalar) cost
.
Then for
any (well-behaved) variation
from this optimal
, we must have
where
ϵ is a scalar.
Applying this principle to our optimization problem, we search for
such that
Thus, for large-
L ,
the quantizer that minimizes
entropy rate
H
y for a given quantization error variance
σ
q2 is the uniform quantizer. Plugging
into
[link] , the rightmost integral disappears
and we have
It is interesting to compare this result to the information-theoretic
minimal average rate for transmission of a continuous-amplitudememoryless source
x of differential entropy
h
x at average distortion
σ
q2 (see Jayant&Noll or Berger):
Comparing the previous two equations, we find that (for a
continous-amplitude memoryless source) uniform quantizationprior to entropy coding requires
more than the theoretically optimum transmission scheme, regardless
of the distribution of
x .
Thus,
0.255 bits/sample (or
dB using the
relationship) is the price paid for memoryless quantization .
Receive real-time job alerts and never miss the right job again
Source:
OpenStax, An introduction to source-coding: quantization, dpcm, transform coding, and sub-band coding. OpenStax CNX. Sep 25, 2009 Download for free at http://cnx.org/content/col11121/1.2
Google Play and the Google Play logo are trademarks of Google Inc.
Notification Switch
Would you like to follow the 'An introduction to source-coding: quantization, dpcm, transform coding, and sub-band coding' conversation and receive update notifications?