

| << Chapter < Page | Chapter >> Page > |
Implementation of Blind Source Separation:
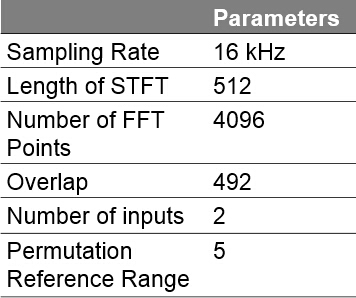
When implementing the Blind Source Separation algorithm, we chose the following parameters,
Result of our Blind Source Separation:
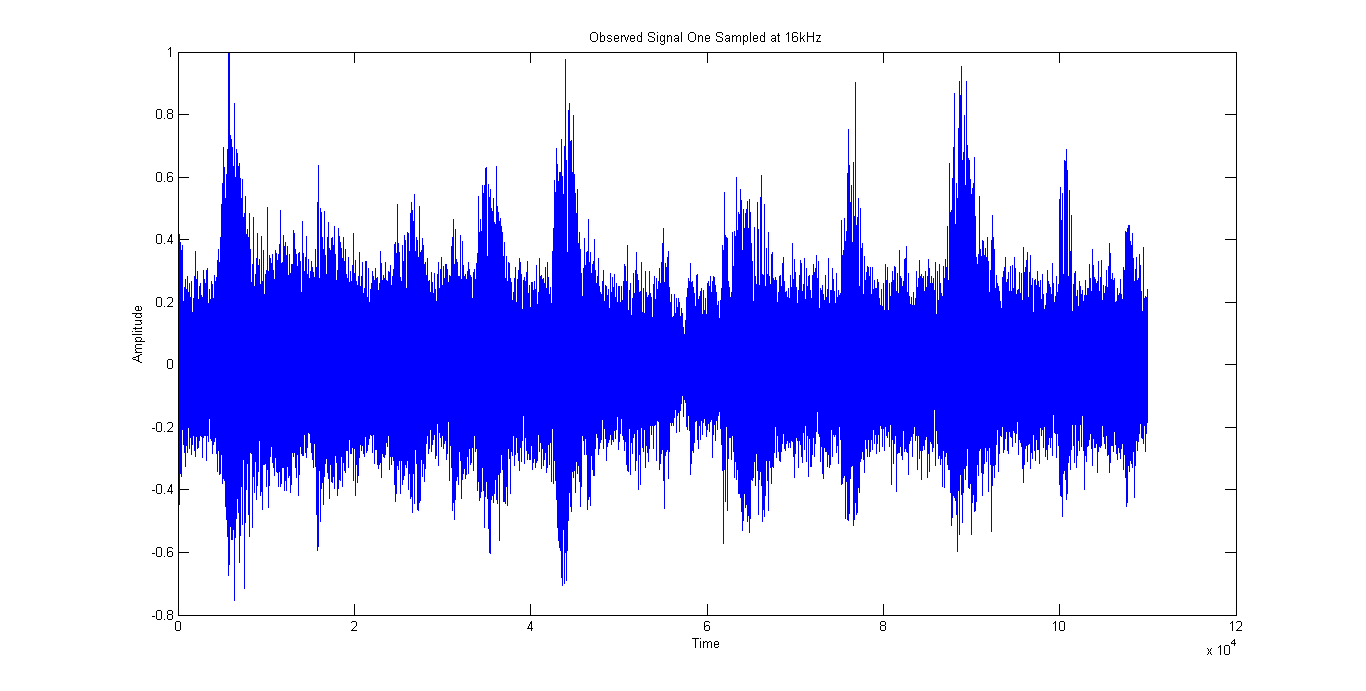
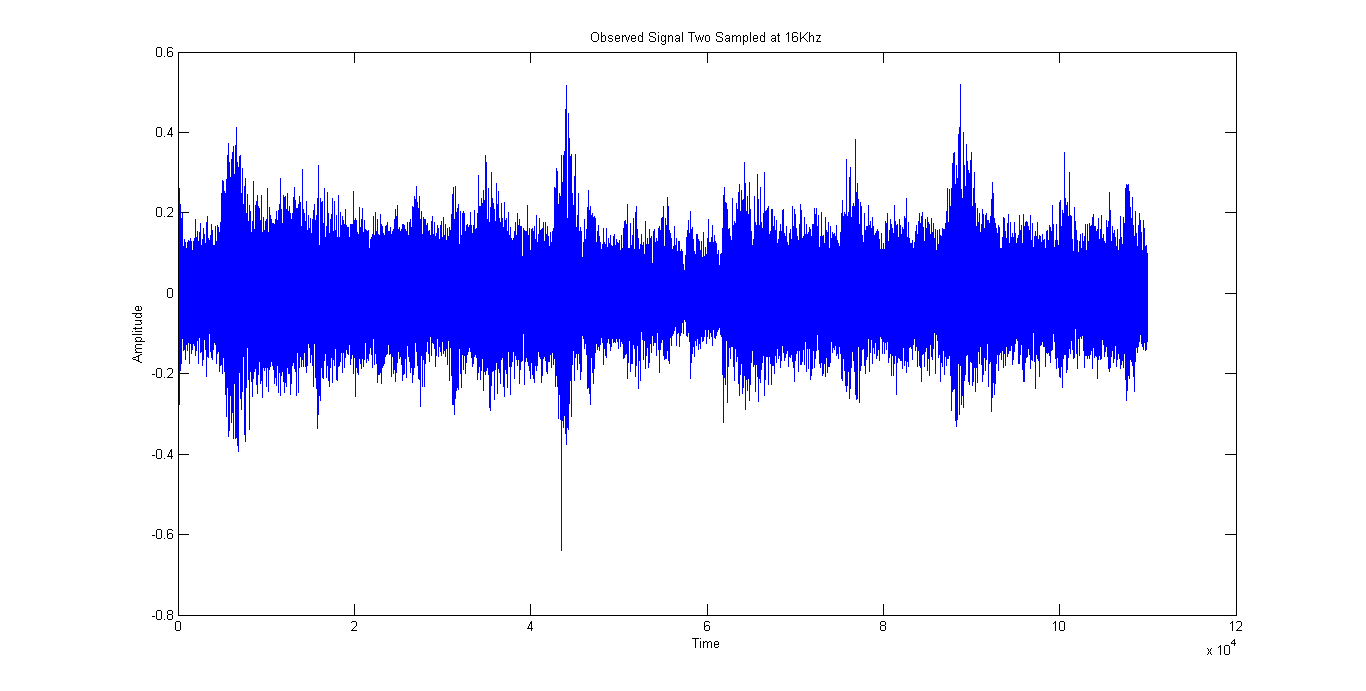
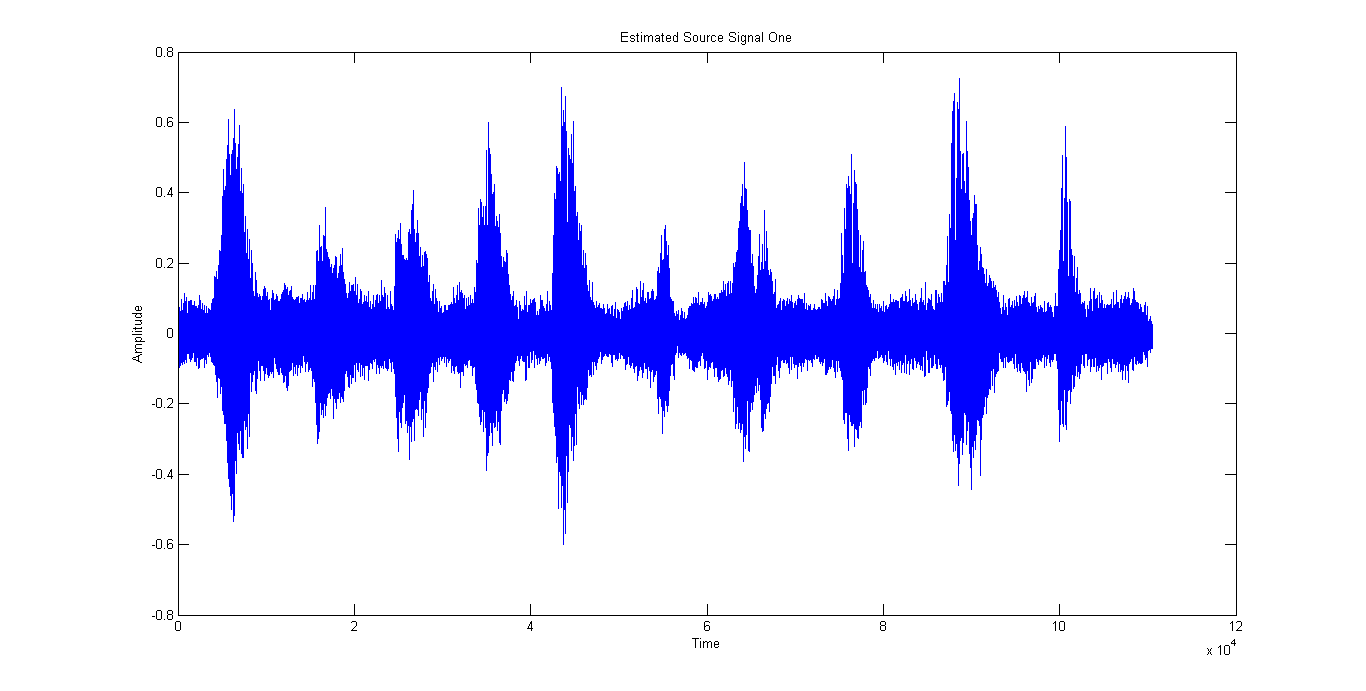
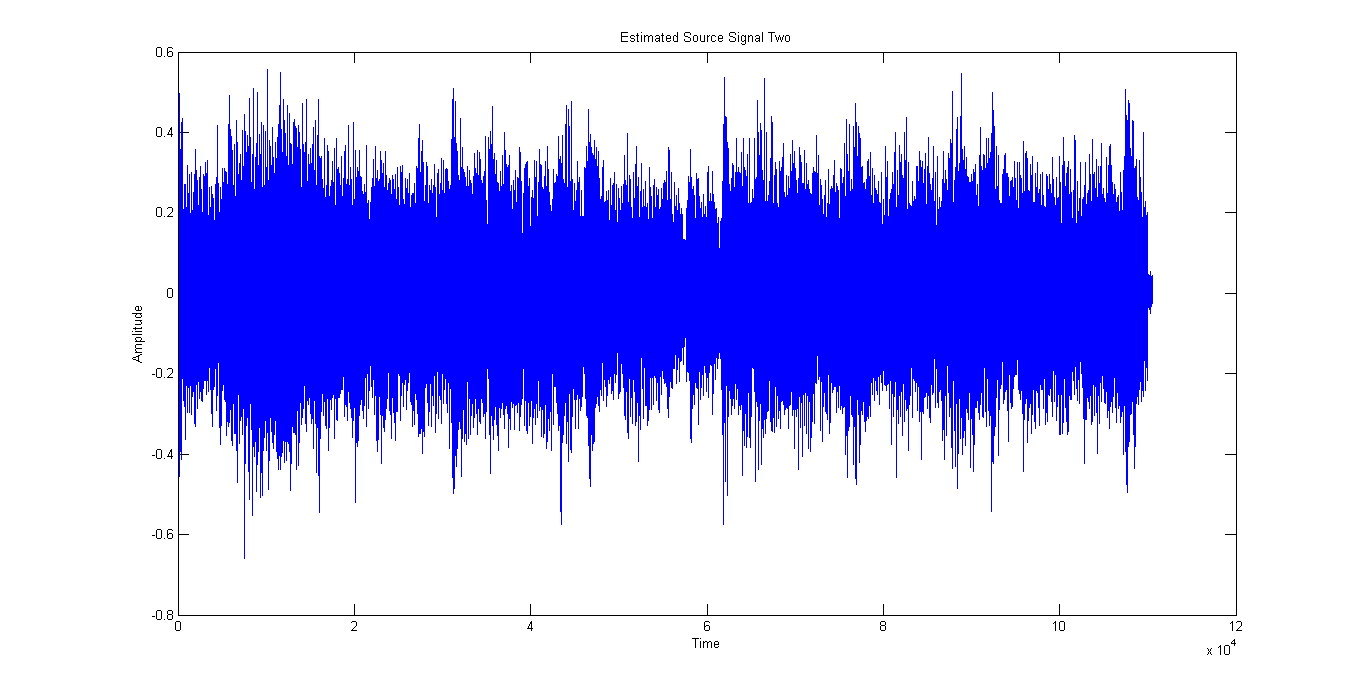
Figure 2 and Figure 3 show the mixed signals observed at the 1 st microphone and the 2 nd microphone respectively. The mixed signal is a recording of a person counting from zero to ten with instrumental music playing in the background. The intermittent spikes in the mixed signal represents the person counting while the continuous, small-amplitude signal represents the instrumental music.
After applying the Blind Source Separation algorithm, we obtain two independent signals shown in Figure 4 and Figure 5 respectively. These two signals are very distinct from each other. The output signal 1 shown in Figure 4 consists mainly of the person counting whereas the output signal 2 shown in Figure 5 is primarily the instrumental music.
Implementation of Neural Network:
Since we need our neural network to perform binary classification, we used 512 nodes for the input layer, 25 nodes for the hidden layer, and 2 nodes for the output layer.
We used 10,000 positive training examples and 10,000 negative training examples to train our neural network. The positive training examples mainly consist of audio file containing examples of human speech such as news broadcasting. The negative training examples mainly consist of examples of non-human speech such as instrumental music.
After taking 512 point Short-Time Fourier Transform, we place our training sets into a 20,000-by-512 matrix where each row represents a single training example. Then we used the backpropagation and gradient descent algorithm described in the section above to train our neural network. We used 70% of the training examples for training, 15% of the training examples for validation, and another 15% for testing.
Result of Our Training of Neural Network:
After employing backpropagation algorithm and gradient descent algorithm to train our neural network, we get the following test results:
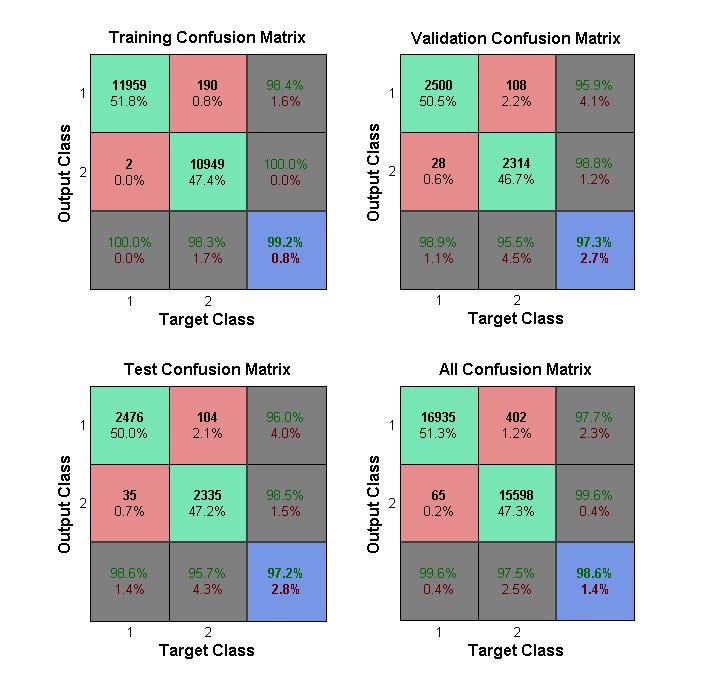
As our neural network is a binary classification model, our output is a vector containing two entries. The first entry represents the probability of the input signal being a human speech and the second entry represents the probability of the input signal being a non-human speech. The two entries sum to one. The overall performance of our neural network is shown in the All Confusion Matrix. The red block showing 0.2% means o.2% of the class 1 examples (human speech) has been incorrectly identified as class 1 (non-human speech). Similarly, the red block showing 1.2% mean 1.2% of the examples of class 2 (non-human speech) has been incorrectly identified as class 1 (human speech). The blue block shows that our neural network is able to distinguish between human speech and non-human speech with an accuracy of 98.6%.
Notification Switch
Would you like to follow the 'Selective transparent headphone' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|
|
|
|