

| << Chapter < Page | Chapter >> Page > |
For reasons that will become clear soon, we chose to compute vowels by creating a continuous, nonoverlapping partition of the signal instead of just separating out vowel content.
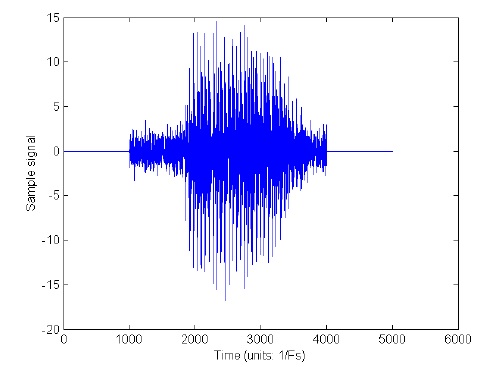
If we go the path of taking the chunk between samples 1000 and 4000 and guessing it's the vowel (which is the best we can do in the "parsing" case), we take into consideration a lot of unwanted noise that will affect our formant guesses. Since roughly half the power in this signal is noise, our results may be corrupted. How might we get around this?
We looked to a partitioning method instead, because it seemed noise-effective to a higher degree. Consider taking the entire signal and dividing it into chunks of 500 samples a piece.
Let's say that we iterate through the sequence of chunks and put the following restriction on our method: "Whenever we see that four chunks of our signal match to the same vowel's formants, we say that vowel is definitively in the signal." If we proceed this way, we notice that samples from 1000 to 2000 will yield two formant pairs that *might* be similar, while the samples between 2000 and 4000 yield four very similar formant pairs because of the vowel content. Since the formants identified in the initial noise don't satisfy the initial restriction, we throw them out. Since the formants identified in the signal itself do satisfy the restriction, we keep them as a means to identifying the vowel. While time-"parsing" can't really deal with the complication of noise, it is easy to see that with this new "partition" method, we are effectively filtering out the effects of inconsistent noise (both external and internal) by throwing out any unreliable data.
Notification Switch
Would you like to follow the 'Vowel recognition using formant analysis' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|