

| << Chapter < Page | Chapter >> Page > |
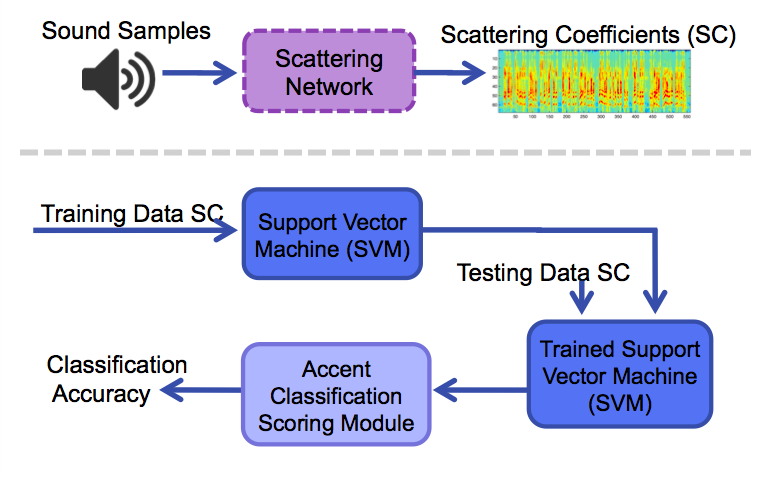
Our system is composed of two main processes: first we use a scattering network to extract the scattering coefficients, and then we train and run a support vector machine to classify the scattering coefficients. We begin with sound samples containing non native speakers reading the same paragraph aloud. A pair of two-second chunks — snippets of the sound sample — are extracted from the beginning of each sample and processed with the Matlab function ScatNet to extract a vector containing scattering coefficients.
These vectors are used to train a support vector machine Matlab function to recognize key characteristics of scattering coefficients of each accent. Scattering coefficients of testing data — obtained using the same method outlined previously — are then processed with the trained support vector machine. The support vector machine compares two accents at a time, and outputs scores between -1 and 1 of how close each sample is to one of the two accents. These scores are then processed with an accent classification scoring module to decide which accent out of all five each testing sample is closest to, and calculate the overall classification accuracy of the system.
Notification Switch
Would you like to follow the 'Accent classification using scattering coefficients' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|