Java JAXP and XSL Transformations (XSLT), Getting Started
Baldwin provides a brief review of XSL Transformations, shows you
how to create and use an identity Transformer object to display a DOM
tree on the screen and write it into an output XML file, and how to
write exception handlers that provide meaningful information in the
event of parser errors and exceptions.
Published: November 18, 2003
By Richard G. Baldwin
Java Programming Notes # 2202
Preface
What is JAXP?
As the name implies, the Java API for XML Processing (JAXP) is an
API designed
to help you write programs for processing XML documents. JAXP is
very important for many reasons, not the least of which is the
fact that it is a critical part of the Java Web Services Developer Pack
(Java WSDP).
This is the second lesson in a series designed to initially help you
understand how to use JAXP,
and to eventually help you understand how to use the Java WSDP.
The first lesson was entitled Java
API for XML Processing (JAXP), Getting Started.
What is XML?
XML is an acronym for the eXtensible Markup Language.
I will not attempt to teach XML in this series of
tutorial lessons. Rather, I will assume that you already
understand
XML, and I will teach you how to use JAXP to write programs for
creating and processing XML documents.
I have published numerous tutorial lessons on XML at Gamelan.com and www.DickBaldwin.com.
You may find it useful to refer to those lessons. In addition, I
provided
a review of the salient aspects of XML in the first lesson in this
series. From time to time, I will also provide background
information regarding XML in the lessons in this series. For
example, I will provide background information on XSL and XSL
Transformations (XSLT) later in this document under General Background
Information on XSLT.
Viewing tip
You may find it useful to open another copy of this lesson in a
separate browser window. That will make it easier for you to
scroll back and forth among the different listings and figures while
you are reading about them.
Supplementary material
I recommend that you also study the other lessons in my extensive
collection of online Java tutorials. You will find those lessons
published at Gamelan.com.
However, as of the date of this writing, Gamelan doesn't maintain a
consolidated index of my Java tutorial lessons, and sometimes
they are difficult to locate there. You will find a consolidated
index at www.DickBaldwin.com.
Rendering XML documents
As of this writing, to my knowledge, Microsoft IE is the only
widely-used web browser that has the ability to do a good job of
rendering XML documents. IE can render XML documents using either
Cascading Style Sheets (CSS) or XSL. Thus, IE provides a good
vehicle for testing XSLT files that you intend to use with JAXP.
What is the W3C?
For purposes of this lesson, the W3C is a
governing body that has published many important documents on XSL and
XSLT, two of which will be referenced later in this document.
What is XSL?
XSL is an acronym for Extensible Stylesheet Language.
According to the W3C, XSL
is
a language for expressing stylesheets. It consists of two parts:
- A language for transforming XML documents, and
- An XML vocabulary for specifying formatting semantics.
Again, according to the W3C,
"An XSL stylesheet specifies the presentation of a class
of XML documents by describing how an instance of the class is
transformed into an XML document that uses the formatting vocabulary."
Separating content from presentation
As you are probably aware by now, one of the primary virtues of XML
is the ability to separate content from presentation.
In other words, an XML document contains structured information, but
does not provide any hints as to how that information should be
rendered for the benefit of a consumer.
What is XSLT?
XSLT is an acronym for XSL Transformations.
According to the W3C,
"This specification defines the syntax and semantics of
XSLT, which is a language for transforming XML documents into other XML
documents.
XSLT is designed for use as part of XSL, which is a stylesheet
language for XML. In addition to XSLT, XSL
includes an XML vocabulary for specifying formatting. XSL specifies
the styling of an XML document by using XSLT to describe how the
document
is transformed into another XML document that uses the formatting
vocabulary.
XSLT is also designed to be used independently of XSL. However,
XSLT is not intended as a completely general-purpose XML transformation
language. Rather it is designed primarily for the kinds of
transformations that are needed when XSLT is used as part of XSL."
Transforming XML to other formats
Because an HTML document can be represented as an XML document, XSLT
can be used to transform XML documents into HTML documents. This
makes it possible to render the information contained in an XML
document using a common HTML Web browser. Thus, one useful way to
view the contents of an XML document is to transform it into an HTML
document and view it using a standard Web browser.
Where does the transformation take place?
When transforming information from an XML document for rendering on
an HTML browser, the transformation can take place anywhere between the
XML document and the browser.
Transforming on the server
For example, an XSLT engine could be written in Java and run as a
servlet, or it could be written as a JavaBeans component and accessed
from a scriptlet in a JavaServer page (JSP).
Transforming at the browser
Or, the transformation could be performed at the browser. For
example, Microsoft IE can be used for this purpose.
A tree structure in memory
As you learned in the previous lesson, a DOM parser can be used to
create a tree structure in memory that represents an XML
document. In Java, that tree structure is encapsulated in an
object of the interface type Document. Document
and its superinterface Node declare numerous methods. As
is always the case, classes that implement Document must
provide concrete definitions of those methods.
Many operations are possible
Thus, given an object of type Document, there are many
methods that
can be invoked on the object to perform a variety of operations.
For example, it is possible to move nodes from one location in the tree
to another location in the tree, thus rearranging the structure of the
XML document represented by the Document object. It is
also possible to delete nodes, and to insert new nodes. As you
saw in the sample program in the previous lesson, it is also possible
to
recursively traverse the tree, extracting information about the nodes
along
the way.
I showed you ...
In the previous lesson, I showed you how to:
- Use JAXP, DOM, and an input XML file to create a Document object
that represents the XML file.
- Recursively traverse the DOM tree, gathering information about
each node in the tree along the way.
- Use the information about the nodes to create a new XML file that
represents the Document object.
The unmodified Document object represented the original XML
file in the previous lesson. The DOM tree was not modified in
that example. The final XML file represented the unmodified Document
object, which represented the original XML file. Therefore, the
final XML file was functionally equivalent to the original XML file.
Something of an overkill
The things that you learned in the previous lesson about traversing
the tree structure and gathering information about each node in the
tree will serve you well in the future. However, if all you need
to do is to write an output XML file that represents a DOM tree, there
is an easier way to do that using XSLT. That is the primary topic
of this lesson.
For simplicity, I elected not to show you how to write exception
handlers that produce meaningful output in the event of parser errors
in the previous lesson. I will also cover that topic in this
lesson.
Nothing fancy intended
The sample program that I will explain in this lesson is not
intended to do anything fancy. It is intended simply to introduce
you to the
use of XSLT to transform DOM objects in Java programs.
Discussion
and Sample Code
The sample program consists of a single class named Xslt01.
For purposes of illustration, the program operates on two XML
files. One of the XML files is named Xslt01.xml.
The other XML file is named Xslt01bad.xml. The first XML
file is well formed, and is used to illustrate the behavior of the
program in the absence of parser errors. The second XML file is
not well formed, and is used to illustrate the behavior of the program
in the face of parser errors.
(You could, of course, use the program to operate on
other XML files of your own design.)
As is often the case, I will discuss the program code in
fragments. Complete listings of all three files are shown in
Listings 9, 10, and 11 near the end of the lesson.
The XML file named Xslt01.xml
I will begin my discussion with the XML file named Xslt01.xml.
A complete listing of this file is shown in Listing 10 near the
end of the lesson. This is a relatively simple XML file.
Assuming that you understood the material in the previous lesson, there
should be no surprises in the file named Xslt01.xml. This
file will be used to test the program for the case where there are no
parser errors.
The XML file named Xslt01bad.xml
A complete listing of the file named Xslt01bad.xml is shown in
Listing 11 near the end of the lesson. This file is not well
formed. It is missing a right angle bracket at the end of line 6,
resulting in a bad end tag for the element named line.
Again, assuming that you understood the material in the previous
lesson, there should be no surprises in the file named Xslt01bad.xml.
This file will be used to test the program for the case where there are
parser errors.
The class named Xslt01
The entire program in contained in a class named Xslt01.
A complete listing of the program is shown in Listing 9 near the
end of the lesson.
Behavior of the program
This program is a modification of the program named Dom02 that
was discussed in the previous lesson. The program was modified to
use
an identity XSL Transformer object to format an output XML
file in
place of a call to Dom02Writer, as was the case in the previous
program.
This modification resulted in a much simpler and probably more reliable
program.
The program was also modified to display the output XML on the Standard
Output Device (typically the screen) as well as to provide
meaningful output in the event of a parsing error.
This program shows you how to:
- Create a Document object using JAXP, DOM, and an input
XML file.
- Create an identity XSL Transformer object.
- Use the identity Transformer object to display the XML
represented by the Document object on the Standard Output
Device.
- Use the identity Transformer object to write the XML
represented by the Document object into an output file.
- Provide meaningful output in the case of a parser error.
Operation of the program
The program requires two command-line arguments. The input XML
file name is provided by the user as the first command-line
argument.
The output XML file name is provided by the user as the second
command-line
argument.
Get a DOM parser object
The program begins by instantiating a DOM parser object of type DocumentBuilder
based on JAXP. The parser is configured as a non-validating
parser.
Create a DOM tree as a Document object
The program uses the parse method of the parser object to parse
an XML file specified on the command line. The parse method
returns an object of type Document that represents the parsed
XML file.
Get an identity Transformer object
Then the program gets a TransformerFactory object and uses
that object to get an identity Transformer object capable of
performing a copy of a source to a result.
Get a Source object
Following this, the program uses the Document object to get a DOMSource
object that implements the Source interface, and acts as a
holder for a transformation source tree in the form of a DOM tree.
Get a Result object
Then the program gets a StreamResult object that implements
the Result interface, and points to the standard output
device. This object acts as a holder for a transformation result.
Transform the DOM tree
Having gone through the preparation steps, the program uses the Transformer
object, the DOMSource object, and the StreamResult object
to transform the DOM tree to text and display it on the standard output
device (the screen).
Having transformed the Document on the screen, the program gets
another StreamResult object that points to an output
file.
Then it transforms the DOM tree to XML text, and writes it into the
output
file.
Handle errors and exceptions
The program catches and handles a variety of different types of errors
and exceptions and provides meaningful output in the event of parser
errors. An XML document that is not well formed is used to
illustrate the ability
to display meaningful information in the event of a parser error.
Miscellaneous comments about the program
The program was tested using SDK 1.4.2 and WinXP with two different XML
files. The XML file named Xslt01.xml is well formed, and
is shown in Listing 10 near the end of the lesson.
The XML file named Xslt01bad.xml is not well formed and is
shown in Listing 11 near the end of the lesson. This file was
purposely corrupted, and is missing a right angle bracket in the
closing tag of a line
element. This file is used to test for parser errors. I
will show you the output produced by this file later in the lesson
under
the discussion of the catch block for exceptions of type SAXParseException.
Let's see some code
The program named Xslt01 begins in Listing 1, which shows the
beginning of the class definition and the beginning of the main
method.
public class Xslt01{
public static void main(String argv[]){
if (argv.length != 2){
System.err.println(
"usage: java Xslt01 fileIn fileOut");
System.exit(0);
}//end if
Listing 1
|
The code in Listing 1 simply checks to confirm that the user has
entered the correct number of command-line arguments, and aborts if the
user has failed to enter the correct number.
Steps for creating a Document object
As you will recall from the previous lesson, three steps
are required to create a Document object:
- Create a DocumentBuilderFactory object
- Use the DocumentBuilderFactory object to create a DocumentBuilder
object
- Use the parse method of the DocumentBuilder object
to create a Document object
These three steps are illustrated by the three statements in Listing
2.
(We will probably see these three statements in many different
programs
in this series of lessons.)
try{
DocumentBuilderFactory docBuildFactory =
DocumentBuilderFactory.newInstance();
DocumentBuilder parser =
docBuildFactory.newDocumentBuilder();
Document document = parser.parse(
new File(argv[0]));
Listing 2
|
The DocumentBuilderFactory Class
Reviewing some of what you learned in the previous lesson, the DocumentBuilderFactory
class
"Defines a factory API that enables applications to
obtain a parser that produces DOM object trees from XML documents."
The DocumentBuilderFactory class extends Object, and
defines about fifteen methods, one of which is a static method
named newInstance. The newInstance method is used
to create an object of the DocumentBuilderFactory class (as
shown in Listing 2).
The class also defines the newDocumentBuilder instance method,
which is used to create objects of the DocumentBuilder class (also
shown in Listing 2).
The DocumentBuilder Class
The DocumentBuilder class
"Defines the API to obtain DOM Document instances from
an
XML document."
This class also extends Object, and defines about
ten methods, which include several overloaded versions of the parse
method. When the parse method is invoked and passed an
input source containing XML, the method returns a Document
object (DOM tree) that represents the XML.
(In Listing 2, the parse method is passed a
reference to a File object that represents the input XML file.)
The Document interface
Document is an interface in the org.w3c.dom package,
which extends the Node interface belonging to the same
package. When we invoke the parse method, it returns a
reference to an object instantiated from a class that implements the Document
interface.
(The reference is returned as type Document, not
as the name of the class from which the object was actually
instantiated. Because Document extends Node,
that object could also be treated as type Node when
appropriate.)
According to Sun:
"The Document interface represents the entire HTML or
XML
document. Conceptually, it is the root of the document tree, and
provides
the primary access to the document's data."
Steps for creating a Transformer object
This information is new to this lesson. The following two steps
are required to create an identity Transformer object.
- Create a TransformerFactory object by invoking the
static newInstance method of the TransformerFactory class.
- Invoke the newTransformer method on the TransformerFactory
object.
These two steps are illustrated by the code in Listing 3.
//Get a TransformerFactory object
TransformerFactory xformFactory =
TransformerFactory.newInstance();
//Get an XSL Transformer object
Transformer transformer =
xformFactory.newTransformer();
Listing 3
|
The TransformerFactory class
A TransformerFactory instance can be used to create Transformer and
Templates objects.
(This lesson does not discuss Templates
objects.
That is a topic for a future lesson.)
In a programming style that should by now be familiar, this class
provides a static method named newInstance. Invocation of
the newInstance method returns a reference to a new instance of
TransformerFactory.
The newTransformer method
A TransformerFactory object provides two overloaded versions
of the newTransformer method. Invocation of the version
of newTransformer that takes no parameters (on an instance
of TransformerFactory) returns a reference to a new Transformer
object that performs a
copy of a source to a result. Some authors refer
to
this as the identity transform.
The code in Listing 3 produces such a Transformer object, and
saves the object's reference in a variable named transformer.
The other overloaded
version of the newTransformer method takes a parameter that
represents an XSL
stylesheet, and returns a Transformer object that implements
the instructions
in the stylesheet. I will show you how to use that version is a
future
lesson.
The Transformer class
Here is some of what Sun has to say about an object of the Transformer
class:
"An instance of this abstract class can transform a
source tree into a result tree.
An instance of this class can be obtained with the
TransformerFactory.newTransformer method. This instance may then be
used to process XML from a variety of
sources and write the transformation output to a variety of sinks."
The transform method
The transform method of the Transformer class is
partially described in Figure 1.
public abstract void transform(
Source xmlSource,
Result outputTarget)
throws TransformerException
Process the source tree to the output result.
Parameters:
xmlSource - The input for the source tree.
outputTarget - The output target.
Figure 1
|
As you can see, this method requires two parameters:
- A reference to an object of type Source
- A reference to an object of type Result
The method processes the Source to produce the Result.
The Source interface
Source is an interface, not a class. Sun has this to say
about the Source interface:
"An object that implements this interface contains the
information needed to act as source input (XML source or transformation
instructions)."
(Note that the reference to transformation instructions
in the above quotation is a reference to the input parameter to the
second overloaded version of the newTransformer method
discussed earlier. Again, I will show you how to use this version
in a future lesson.)
In this program, I will create and use an object of the DOMSource
class as the source for the transformation. (The DOMSource
class implements the Source interface.)
The DOMSource class
Here is what Sun has to say about an object of the DOMSource
class:
"Acts as a holder for a transformation Source tree in
the
form of a Document Object Model (DOM) tree."
The Result interface
Sun has this to say about the Result interface:
"An object that implements this interface contains the
information needed to build a transformation result tree."
In this program, I will transform the DOMSource object
into two different Result objects:
- A StreamResult object that points to the Standard Output
Device (typically the screen).
- A StreamResult object that points to the output file.
The StreamResult class
Sun has this to say about the StreamResult class:
"Acts as an holder for a transformation result, which
may be
XML, plain Text, HTML, or some other form of markup."
Get a DOMSource object
Listing 4 shows the code that gets a DOMSource object, which
represents the Document object.
DOMSource source = new DOMSource(document);
Listing 4
|
The DOMSource class provides several different overloaded
constructors, one of which requires a single incoming parameter of type
Node.
Recall that the variable document contains a reference to an
object
that implements the Document interface, which is a subinterface
of
the Node interface. Thus, document satisfies the
parameter type requirement for the constructor shown in Listing 4.
The DOMSource object produced in Listing 4 will later be
transformed into two different Result objects.
Get a StreamResult object
The statement in Listing 5 gets a StreamResult object that
points to the Standard Output Device.
StreamResult scrResult =
new StreamResult(System.out);
Listing 5
|
The StreamResult class provides several overloaded
constructors, one of which requires an incoming parameter of type OutputStream.
System.out contains a reference to an object of type PrintStream,
which is a subclass of OutputStream. Therefore, System.out
satisfies the parameter type requirement for one of the overloaded
constructors
of StreamResult.
Transform the DOMSource to text on the screen
The statement in Listing 6 invokes the transform method of the
Transformer class to transform the DOMSource object to
text
on the screen.
transformer.transform(source, scrResult);
Listing 6
|
The two parameters to the transform method shown in Listing 6
satisfy the parameter type requirements (Source and Result)
shown earlier in Figure 1.
Because the DOMSource object represents the Document
object, the code in Listing 6 transforms the Document object to
the screen. Since the Document object represents the
original XML file, this effectively transforms the contents of the
original XML file to the screen.
The screen output
The statement shown in Listing 6 produced the screen output shown in
Figure 2.
<?xml version="1.0" encoding="UTF-8"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
Figure 2
|
If you compare Figure 2 with the input XML file shown in Listing 10
near the end of the lesson, you will see that it matches in all
respects but one.
The one line that doesn't match is the XML declaration in the first
line
of Figure 2 and Listing 10.
The XML declaration
The XML declaration is really not part of the XML data. Rather,
the XML declaration provides information to the processor being used to
process the XML data. I don't believe that the XML declaration
becomes a part of the DOM tree structure.
(Recall that in the previous lesson, I used a separate
statement to write the XML declaration into the output file before
beginning the process of writing data in the output file based on data
in the DOM tree.)
The encoding attribute in the XML declaration shown in Figure
2
is optional. I elected not to include it in the original XML
file.
The author of the transform method of the Transformer
class
elected to include it in the transformed output. That is why it
appears
in Figure 2 and does not appear in Listing 10.
Write an output XML file
The three statements in Listing 7 perform the following three actions
in order:
- Get an output stream for the output XML file.
- Get a StreamResult object that points to the output file.
- Transform the DOMSource object to text in the output file.
PrintWriter outStream = new PrintWriter(
new FileOutputStream(argv[1]));
StreamResult fileResult =
new StreamResult(outStream);
transformer.transform(source, fileResult);
}//end try block
Listing 7
|
The output file
Figure 3 shows the contents of the output file produced by Listing 7.
<?xml version="1.0" encoding="UTF-8"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
Figure 3
|
As you might have surmised, the contents of the output file shown in
Figure 3 match the screen output shown in Figure 2. Also, with
the exception of the optional encoding attribute in the XML
declaration, the contents of the output file match the contents of the
original XML file shown in Listing 10.
End of the try block
Listing 7 also signals the end of the try block and the end of
the code required to apply an identity XSL Transformation to a Document
object.
Now you know how to use an identity transform to either display the XML
data encapsulated in a Document object, or to cause that XML
data
to be written into a new XML file.
The remainder of this lesson deals with errors and exceptions, with
particular emphasis on providing meaningful output in the event of a
parser error.
Potential errors and exceptions
If we scan back through the code, we can identify the following
expressions related to XML processing that have the potential of
throwing errors and exceptions (I will omit I/O exceptions from
this discussion).
A review of the Sun documentation reveals that these expressions can
throw the errors and exceptions shown.
- parser.parse(new File(argv[0]) throws SAXException if any
parse errors occur.
- docBuildFactory.newDocumentBuilder() throws ParserConfigurationException
if a DocumentBuilder cannot be created which satisfies the
configuration requested.
- xformFactory.newTransformer() throws TransformerConfigurationException
- May throw this during the parse when it is constructing the Templates
object and fails.
- transformer.transform(source, scrResult) throws TransformerException
if an unrecoverable error occurs during the course of the
transformation.
- transformer.transform(source, fileResult) throws TransformerException
if an unrecoverable error occurs during the course of the
transformation.
- TransformerFactory.newInstance() throws TransformerFactoryConfigurationError
if the implementation is not available or cannot be instantiated.
- DocumentBuilderFactory.newInstance() throws FactoryConfigurationError
if the implementation is not available or cannot be instantiated.
Handling errors and exceptions
The remaining code in the program provides specific catch blocks for
some, but not all of the exceptions and errors listed above.
(A general Exception catch block is provided to
handle those errors and exceptions for which specific catch blocks are
not provided.)
The SAXException class
The classes of primary interest in this lesson are the SAXException
class and a subclass of that class named SAXParseException.
Here is part of what Sun has to say about the SAXException
class (boldface added by this author for emphasis):
"Encapsulate a general SAX error or warning. ... This
class can contain basic error or warning information from either the
XML parser or the application: a parser writer or application writer
can subclass it to provide additional functionality. SAX handlers may
throw this exception or any exception subclassed from it.
If the application needs to pass through other types of
exceptions, it must wrap those exceptions in a SAXException or an
exception derived from a SAXException.
If the parser or application needs to include information about
a specific location in an XML document, it should use the
SAXParseException subclass."
The SAXParseException class
The SAXParseException class is a subclass of SAXException.
An object of SAXParseException can
"Encapsulate an XML parse error or warning. ... This
exception will include information for locating the error in the
original XML document."
The list that I showed you earlier indicated that the parse
method of the DocumentBuilder class throws SAXException.
That means that it can also throw any exception that is a subclass of SAXException.
As it turns out, the parse method actually throws a SAXParseException,
for at least some of the possible parsing error types.
The SAXParseException handler
Listing 8 shows the entire catch block for handling an exception of
type SAXParseException.
catch(SAXParseException saxEx){
System.err.println("\nSAXParseException");
System.err.println("Public ID: " +
saxEx.getPublicId());
System.err.println("System ID: " +
saxEx.getSystemId());
System.err.println("Line: " +
saxEx.getLineNumber());
System.err.println("Column:" +
saxEx.getColumnNumber());
System.err.println(saxEx.getMessage());
Exception ex = saxEx;
if(saxEx.getException() != null){
ex = saxEx.getException();
System.err.println(ex.getMessage());}
}//end catch
Listing 8
|
Of particular interest is the invocation of the five get
methods on the exception object for the purpose of getting and
displaying information about the exception.
Listing 11 contains an XML file named Xsl01bad.xml for which a
right angle bracket was purposely omitted from the end tag on the sixth
line of text. This caused the XML document to not be well formed
because
the line element on the sixth line is malformed.
The screen output
When this program was used to process the corrupt file named Xsl01bad.xml,
the code in Listing 8 produced the output shown in Figure 4. (Note
that I manually inserted a line break to force some of the output to
fit in this narrow publication format.)
SAXParseException
Public ID: null
System ID: file:C:/jnk/Xslt01bad.xml
Line: 7
Column:-1
Next character must be ">" terminating
element "line".
Figure 4
|
You should be able to correlate each line of output in Figure 4 with
the statements in Listing 8.
The -1 reported for the column number in Figure 4 indicates that the
column number was "not available" to the method named getColumnNumber.
The reported line number value of 7 is also one line beyond the
actual line where the error occurs in the XML document.
(My interpretation of this situation is that the parser
considered the error to be before the first character in line 7 instead
of at the end of line 6. The error because apparent to the parser
when it encountered the left angle bracket for a new start tag without
the previous end tag having been properly terminated with a right angle
bracket.)
Parsing with Internet Explorer
For comparison purposes, Figure 5 shows the result of attempting to
parse the same corrupt XML file using Internet Explorer.
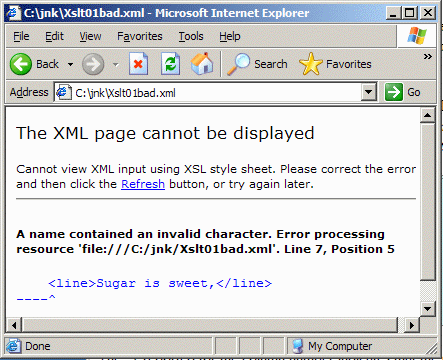
Figure 5 Parsing error as per Internet Explorer
As you can see, the IE parser considered the error to be at the
beginning of line 7 instead of at the end of line 6. However, it
was able to provide a column number. (It also provides a nice
graphic display showing the location of the error.)
Wrapped exceptions
As indicated in the earlier quotations from Sun, objects of the classes
SAXException and SAXParseException can wrap other
exceptions. The mechanism for getting and displaying the wrapped
exception, if any, is shown by the invocation of the getException
method on the SAXParseException
object in Listing 8. According to Sun, the getException
method,
which is inherited from SAXException, "returns the embedded
exception,
if any." The embedded exception is returned as type Exception.
The screen output in Figure 4 indicates that there was no embedded
exception in this sample case.
The remaining exception handlers
You can view the remaining exception handlers in Listing 9 near the end
of the lesson. There is nothing unusual about any of them.
Therefore, I won't discuss them in detail.
Run the Program
I encourage you to copy the code and XML data from Listings 9, 10,
and 11 into your text editor. Compile the program and execute
it. Experiment with it, making changes, and observing the results
of your
changes.
In this second lesson on Java JAXP, I began by providing a brief
review of XSL and XSL Transformations (XSLT).
Then I showed you how to create an identity Transformer
object, and how to use that object to:
- Display a DOM tree structure on the screen in XML format.
- Write the contents of a DOM tree structure into an output XML
file.
Following that, I showed you how to write exception handlers that
provide meaningful information in the event of errors and exceptions,
with particular emphasis on parser errors and exceptions.
In the next lesson, I will show you how to write a program to
display a DOM tree on the screen in a format that is much easier to
interpret than raw XML code.
Complete Program Listings
Complete listings of the Java class and the XML documents discussed in
this lesson are shown in Listings 9, 10, and 11 below.
/*File Xslt01.java
Copyright 2003 R.G.Baldwin
This is a modification of the program named
Dom02.java that was discussed in an earlier
lesson. The program was modified to use an
identity XSLT transform to format the output XML
file in place of a call to Dom02Writer. This
results in a much simpler program.
The program was also modified to display the
output XML on the Standard Output Device.
The program was also modified to provide
meaningful output in the event of an error.
This program shows you how to:
1. Create a Document object using JAXP, DOM, and
an input XML file.
2. Create an identity XSL Transformer object.
3. Use the identity XSL Transformer object to
display the XML represented by the Document
object on the Standard Output Device.
3. Use the identity XSL Transformer object to
write the XML represented by the Document
object into an output file.
The input XML file name is provided by the user
as the first command-line argument. The output
XML file name is provided by the user as the
second command-line argument.
The program instantiates a DOM parser object
based on JAXP. The parser is configured in the
default non-validating configuration.
The program uses the parse() method of the parser
object to parse an XML file specified on the
command line. The parse method returns an object
of type Document that represents the parsed XML
file.
Then the program gets a TransformerFactory object
and uses that object to get a default identity
Transformer object capable of performing a copy
of the source to the result.
Then the program uses the Document object to get
a DOMSource object that acts as a holder for a
transformation Source tree in the form of a
Document Object Model (DOM) tree.
Then the program gets a StreamResult object that
points to the standard output device. This
object acts as a holder for a transformation
result.
Then the program uses the Transformer object,
the DOMSource object, and the StreamResult object
to transform the DOM tree to text and display it
on the standard output device.
Then the program gets another StreamResult object
that points to an output file, transforms the
DOM tree to text, and writes it into the output
file.
The program catches a variety of different types
of errors and exceptions and provides meaningful
output in the event of an error or exception.
Tested using SDK 1.4.2 and WinXP with two
differentan XML files. The XML file named
Xslt01.xml is well formed, and reads as follows:
<?xml version="1.0"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
The XML file named Xslt01bad.xml is not well
formed and reads as follows:
<?xml version="1.0"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<!--Following line missing > -->
<line>Violets are blue.</line
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
This file is purposely missing a right angle
bracket in the closing tag of a line element,
and is used to test for parser errors.
When processing the well formed XML file, the
program produces the following text on the
Standard Output Device:
<?xml version="1.0" encoding="UTF-8"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
When processing the well formed XML file, the
program produces an output XML file that reads
as follows:
<?xml version="1.0" encoding="UTF-8"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
When processing the bad XML file, the program
aborts with the following error message on the
standard error device:
SAXParseException
Public ID: null
System ID: file:C:/jnk/Xslt01bad.xml
Line: 7
Column:-1
Next character must be ">" terminating
element "line".
Note that I manually inserted line breaks into
the error message above to force it to fit into
this narrow publication format.
************************************************/
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import
javax.xml.parsers.FactoryConfigurationError;
import
javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerException;
import javax.xml.transform.
TransformerConfigurationException;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.File;
import java.io.PrintWriter;
import java.io.FileOutputStream;
public class Xslt01 {
public static void main(String argv[]){
if (argv.length != 2){
System.err.println(
"usage: java Xslt01 fileIn fileOut");
System.exit(0);
}//end if
try{
//Get a factory object for DocumentBuilder
// objects with default configuration.
DocumentBuilderFactory docBuildFactory =
DocumentBuilderFactory.newInstance();
//Get a DocumentBuilder (parser) object
DocumentBuilder parser =
docBuildFactory.newDocumentBuilder();
//Parse the XML input file to create a
// Document object that represents the
// input XML file.
Document document = parser.parse(
new File(argv[0]));
//Get a TransformerFactory object
TransformerFactory xformFactory =
TransformerFactory.newInstance();
//Get an XSL Transformer object
Transformer transformer =
xformFactory.newTransformer();
//Get a DOMSource object that represents
// the Document object
DOMSource source = new DOMSource(document);
//Get a StreamResult object that points to
// the screen. Then transform the DOM
// sending XML to the screen.
StreamResult scrResult =
new StreamResult(System.out);
transformer.transform(source, scrResult);
//Get an output stream for the output XML
// file.
PrintWriter outStream = new PrintWriter(
new FileOutputStream(argv[1]));
//Get a StreamResult object that points to
// the output file. Then transform the DOM
// sending XML to to the file
StreamResult fileResult =
new StreamResult(outStream);
transformer.transform(source, fileResult);
}//end try block
catch(SAXParseException saxEx){
System.err.println("\nSAXParseException");
System.err.println("Public ID: " +
saxEx.getPublicId());
System.err.println("System ID: " +
saxEx.getSystemId());
System.err.println("Line: " +
saxEx.getLineNumber());
System.err.println("Column:" +
saxEx.getColumnNumber());
System.err.println(saxEx.getMessage());
Exception ex = saxEx;
if(saxEx.getException() != null){
ex = saxEx.getException();
System.err.println(ex.getMessage());}
}//end catch
catch(SAXException saxEx){
//This catch block may not be reachable.
System.err.println("\nParser Error");
System.err.println(saxEx.getMessage());
Exception ex = saxEx;
if(saxEx.getException() != null){
ex = saxEx.getException();
System.err.println(ex.getMessage());}
}//end catch
catch(ParserConfigurationException parConEx){
System.err.println(
"\nParser Config Error");
System.err.println(parConEx.getMessage());
}//end catch
catch(TransformerConfigurationException
transConEx){
System.err.println(
"\nTransformer Config Error");
System.err.println(
transConEx.getMessage());
Throwable ex = transConEx;
if(transConEx.getException() != null){
ex = transConEx.getException();
System.err.println(ex.getMessage());}
}//end catch
catch(TransformerException transEx){
System.err.println(
"\nTransformation error");
System.err.println(transEx.getMessage());
Throwable ex = transEx;
if(transEx.getException() != null){
ex = transEx.getException();
System.err.println(ex.getMessage());}
}//end catch}
catch(Exception e){
e.printStackTrace(System.err);
}//end catch
}// end main()
}// class Xslt01
Listing 9
|
A listing of the file named Xslt01.xml is provided in Listing
10 below.
<?xml version="1.0"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<line>Violets are blue.</line>
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
Listing 10
|
A listing of the file named Xslt01bad.xml is provided in
Listing 11 below. Note the missing right angle bracket at the end
of line 6.
<?xml version="1.0"?>
<bookOfPoems>
<poem PoemNumber="1" DumAtr="dum val">
<line>Roses are red,</line>
<!--Following line missing > -->
<line>Violets are blue.</line
<line>Sugar is sweet,</line>
<line>and so are you.</line>
</poem>
<?processor ProcInstr="Dummy"?>
<!--Comment-->
<poem PoemNumber="2" DumAtr="dum val">
<line>Roses are pink,</line>
<line>Dandelions are yellow,</line>
<line>If you like Java,</line>
<line>You are a good fellow.</line>
</poem>
</bookOfPoems>
Listing 11
|
Copyright 2003, Richard G. Baldwin. Reproduction in whole or
in
part in any form or medium without express written permission from
Richard
Baldwin is prohibited.
About the author
Richard Baldwin
is a college professor (at Austin Community College in Austin, TX) and
private consultant whose primary focus is a combination of Java, C#,
and XML. In addition to the many platform and/or language independent
benefits of Java and C# applications, he believes that a combination of
Java, C#, and XML will become the primary driving force in the delivery
of structured information on the Web.
Richard has participated in numerous consulting projects, and he
frequently provides onsite training at the high-tech companies located
in and around Austin, Texas. He is the author of Baldwin's
Programming Tutorials, which
has gained a worldwide following among experienced and aspiring
programmers. He has also published articles in JavaPro magazine.
Richard holds an MSEE degree from Southern Methodist University
and has many years of experience in the application of computer
technology to real-world problems.
Baldwin@DickBaldwin.com
-end-