Baldwin begins by reviewing the salient aspects of XML. Then he shows you how to (a) use JAXP, DOM, and an input XML file to create a Document object that represents the XML file, (b) recursively traverse the DOM tree, getting information about each node in the tree along the way, and (c) use the information about the nodes to create a new XML file that represents the Document object.
Published: October 21, 2003
By Richard G. Baldwin
Java Programming Notes # 2200
What is JAXP?
As the name implies, the Java API for XML Processing (JAXP) is an
API
provided by Sun designed to help you write programs for processing XML
documents. JAXP is very important for many reasons, not the least
of which is the fact that it is a critical part of the Java Web
Services Developer Pack (Java WSDP). According to Sun,
This is the first lesson in a series designed to initially help you
understand how to use JAXP, and to eventually help you understand how
to use the Java WSDP.
What is XML?
If you have been around Information Technology (IT) for the past several years, it is doubtful that you have escaped hearing about the eXtensible Markup Language (XML). However, if you are like many of the professional programmers who enroll in my Java courses, you may not yet know much about XML.Viewing tip
You may find it useful to open another copy of this lesson in a separate browser window. That will make it easier for you to scroll back and forth among the different listings and figures while you are reading about them.
Supplementary material
I recommend that you also study the other lessons in my extensive collection of online Java tutorials. You will find those lessons published at Gamelan.com. However, as of the date of this writing, Gamelan doesn't maintain a consolidated index of my Java tutorial lessons, and sometimes they are difficult to locate there. You will find a consolidated index at www.DickBaldwin.com.
Purpose of this section
As mentioned earlier, the purpose of this section is to review the salient aspects of XML for those who are unfamiliar with the topic. Those of you who already know about XML can skip ahead to the Preview section. Those of you who are just getting your feet wet in XML (and may have found the XML water to be a little deep) should continue reading this section.
Jargon
Computer people are the world's worst at inventing new jargon. XML people seem to be the worst of the worst in this regard.
Go to an XML convention and everything that you hear will be X-this,
X-that, X-everything. Sometimes I get dizzy just trying to keep
the
various X's separated from one another. In this explanation
of XML, I will try to either avoid the use of jargon, or will explain
the jargon the first time I use it.
So, just what is XML?
There are many definitions and descriptions for XML. I like
the
one given in Figure 1.
| XML gives us a way to create and maintain structured
documents in plain text that can be rendered in a
variety of different ways.
A primary objective of XML is to separate content from presentation. Figure 1 |
I will answer this question by providing an example. A book is typically a structured document.
In its simplest form, a book may be composed of chapters. The chapters may be composed of sections. The sections may contain illustrations and tables. The tables are composed of rows and columns.
Thus, it should be possible to draw a hierarchical diagram that illustrates the structure of a book, and most people who are familiar with books will probably recognize it as such.
What do I mean by "plain text?"
Characters such as the letters of the alphabet and punctuation marks are represented in the computer by numeric values, similar to a simple substitution code that a child might devise.
ASCII is an encoding scheme
For example in one popular encoding scheme (ASCII), the upper-case version of the character "A" is represented by the numeric value 65, a "B" is represented by the value 66, a "C" is represented by 67, etc.
The actual correspondence between the characters and the specific numeric values representing the characters has been described by several different encoding schemes over the years.
ASCII is also an organization
One of the most common and enduring schemes for encoding characters is a scheme that was devised many years ago by an organization known as the American Standards Committee on Information Interchange.
Given the initials of the organization, this encoding scheme is commonly known as the ASCII code.
Figure 2 contains a quotation from one author regarding the ASCII code (or plain text).
| "This stands for American Standards Committee on Information
Interchange. What it means in practice is plain text, that is to say
text which is readable directly without using any special software.
The advantage of ASCII is that it is a lowest common denominator which
can be displayed on any platform. The disadvantage is that it is rather
limited and somewhat boring. The text cannot display bold, italics or
underlined fonts, and there is no scope for graphics or hypertext.
However,
it is simple, ... and is almost idiot-proof as a means of information
exchange. To see a short example of ASCII click HERE, or to
see a journal article in ASCII click HERE." Figure 2 |
XML is not confined to the ASCII code
XML is not confined to the use of the ASCII encoding scheme. Several different encoding schemes can be used.
However, all of them have been selected to make it possible to read a raw XML document without the requirement for any special software (other than perhaps a text editor or the DOS type command).
What is a raw XML document?
A raw XML document is the string of sequential characters that makes up the document, before any specific rendering has been applied to the document.
What do I mean by "rendering?"
In modern computer jargon, rendering typically means to present something for human consumption.
Rendering a drawing
For example, in a computer, drawings and images are nothing more or less than sets of numbers and possibly formulas. Those numbers and formulas, taken at face value, usually mean very little to most human observers.
Recognition by a human observer
When we speak of rendering a drawing or an image, we usually mean that we are going to present it in a way that makes it look like a drawing or an image to a human observer. In other words, we convert the numbers and formulas that comprise the drawing to a set of colored dots (pixels) that a human observer will recognize as a drawing.
Rendering a document
When we speak of rendering a document, we usually mean that we are going to present it in a way that a human will recognize it as a book, a newspaper, or some other document style that can be read by the human observer.
Passing information through typography
Rendering, in this case, often means to present some of the material in boldface, some of the material in Italics, some of the material underlined, some of the material in color, etc. (For example, when you view this document using an HTML browser, it is rendered to show boldface, Italics, color, etc.)
To separate presentation from content
Raw XML doesn't exhibit any of these presentation properties, such as boldface, Italics, or color. Remember, a main objective of XML is to separate presentation from content. XML provides only the content. The presentation of that content must come from somewhere else.
Consider a newspaper
These days, there are at least two different ways to render a newspaper. One way is to print the information (daily news), mostly in black and white, on large sheets of low-grade paper commonly known as newsprint. This is the rendering format that ends up on my driveway each morning.
My online newspaper
Another way to render a newspaper is to present the information on a computer screen, usually in full color, with the information content trying to fight its way through dozens of animated advertisements.
USA Today
For example, here is the sort of rendering format that USA Today provides for the online version of its newspaper. Most of you are probably already familiar with the newsprint rendering of that well known newspaper.
The news doesn't change
The base information for the newspaper doesn't (or shouldn't) change for the newsprint and online renderings. After all, news is news and the content of the news shouldn't depend on how it is presented. What does change is the manner in which that information is presented.
A newspaper is a structured document consisting of pages, columns, etc., which could be maintained using XML.
The great promise of XML
When the information content of a newspaper is created and maintained in XML, that same information content can be rendered on newsprint paper, on your computer screen, on your call phone, or potentially in other formats without having to rewrite the information content.
Not necessarily boring
If you visit the above link to the journal article rendered solely in ASCII, you will probably agree that from a presentation viewpoint it is pretty boring (no offense intended to the author of the article).
However, XML documents created and maintained in plain text need not necessarily be boring.
When you combine a rendering engine with XML ...
It is possible to apply a rendering engine (such as XSL) to the XML content and to render that content in rich and exciting ways. (XSL is an acronym for the Extensible Stylesheet Language, and is an advanced topic that I will be covering in future lessons in this series.)
Separating content from presentation
XML is responsible for maintaining the content, independent of presentation.
A rendering engine, such as XSL, is responsible for rendering that content in ways that are appropriate for the application.
Achieving Structure
So, just how does XML use plain text to create and maintain structure?
Consider the following simple structure that represents a book. (This book certainly wasn't written by me, because it is much too brief.)
The book described by the structure in Figure 3 has two chapters
with some
text in each chapter.
Begin Book Figure 3 |
A simple example
A real book obviously has a lot more structure than this. For example, a typical book will probably have a Forward or a Preface. A typical book will usually have a Table of Contents.
Breaking the structure down further produces paragraphs within the text, words within the paragraphs, etc. Also, a book will frequently have an Alphabetical Index.
However, I am trying to keep this example as simple as possible, so I left those things out.
A primary objective
In the earlier description, I told you "A primary objective of XML is to separate content from presentation."
This separation, and the fact that the XML document is maintained in plain text, makes it possible to share the same physical document among different computers in a way that they all understand. (This is often not true, for example, for documents that are maintained in the proprietary formats of word processing software.)
Many different computers and operating systems
Sharing of a document among different computers is no small accomplishment. Over the years, dozens of different types of computers have been built, operating under different operating systems, and running thousands of different programs.
As a result, the modern computer world is often like being on an island where everyone speaks a different language.
A common language for structured documents
XML attempts to rectify this situation by providing a common language for structured documents.
What Does XML Contribute?
I am going to ease into the technical details later. At this point, suffice it to say that XML provides a definition of a simple scheme by which the structure and the content of a document can be established.
Even I can understand an XML document
The resulting physical document is so simple that any computer (and most humans) can read it with only a modest amount of preparation.
You will sometimes see XML referred to as a "meta" language.
What does meta mean?
In computer jargon, the term meta is often used to identify something that provides information about other information.
Stock and bond price information
For example, consider the listings of stock prices, bond prices, and mutual fund prices that commonly appear in most daily newspapers.
The various tables on the page provide information about the bid and ask prices for the various stock, bond, and mutual fund instruments.
What you need is meta information
But, how do you read those charts? How do you extract information from the charts? You need some information about the information contained in the charts. You need some meta information.
Stock and bond meta information
Usually somewhere on the page, you will find an explanation as to how to interpret the information presented throughout the remainder of the page.
You could probably think of the information contained in the explanation as meta information. It provides information about other information.
What about the alphabetical index in a book?
Is the alphabetical index of a book a form of meta information? Probably so.
For example, the alphabetical index can tell you if the book contains information about XML or other topics of interest to you. If so, it will tell you where in the book you can find that information.
The index can also tell you where to find information about elements and attributes that I will discuss later. So, yes, in my opinion, the alphabetical index in a book provides meta information.
So, why might people refer to XML as a meta language?
If you write a book and maintain its content in XML, XML doesn't tell you how to structure the document that represents your book.
XML provides a set of rules for structuring
Rather, XML provides you with a set of rules that you can use to establish your own structure and content when you create the document that represents your book.
XML is not the language that you use to establish the structure and content of your book. Rather, XML tells you how to create your own language for creating structure and maintaining content.
It is up to you to decide how you will use those rules to define your own language for establishing the structure and content of your book.
Invent your own language
You might say that XML is a language that provides information about a new language that you are free to invent.
Does everyone use a different language?
As it turns out, different groups of people having common interests have gotten together and have used XML to invent a common language by which the persons in the group can create, maintain, and exchange document structure in their areas of interest.
The Chemical Markup Language
For example, a group of chemists has gotten together and has used the XML rules to invent a common language by which they create and exchange structured documents on chemistry.
MathML
Similarly, a group of mathematicians has gotten together and has invented a common language by which they create and exchange structured documents on mathematics.
XML is easily transported
If you follow the rules for creating an XML document, the document that you create can easily be transported among various computers and rendered in a variety of different ways.
Two different renderings
For example, you might want to have two different renderings of your book. One rendering might be in conventional printed format and the other rendering might be in an online format.
No requirement to modify the XML source document
The use of XML makes it practical to render your book in two or more different ways without any requirement to modify the original document that you produce.
This leads to the name: eXtensible Markup Language or XML.
Applying XML
Now let's look at a couple of sample XML documents, either of which might reasonably represent the simple book presented earlier.
The first sample XML document is shown in Listing 1.
<?xml version="1.0"?> |
This example shows typical XML syntax.
Compare with earlier book description
If you compare this example with the informal book example given earlier in Figure 3, you should see a one-to-one correspondence between the "elements" in this XML document and the informal description of the book presented earlier.
An improved example
Listing 2 shows a modest improvement over the XML code in Listing 1, by including an "attribute" named number in each of the chapter elements. This attribute contains the chapter number and is part of the information that defines the structure of the book.
<?xml version="1.0"?> |
The book represented by the XML code in Listing 2 has two chapters with some text in each chapter. This XML code contains an attribute that describes the chapter number in each chapter element.
Now consider a new jargon word: tag.
What is a tag?
The common jargon for XML items (such as those shown in Figure 4) enclosed in angle brackets is tag. (You may be familiar with this jargon based on HTML experience.)
<book> Figure 4 |
Start tags and end tags
The tag shown in Figure 4 is often referred to as a start tag or a beginning tag.
The tag shown in Figure 5 is often referred to as an end tag.
</book> Figure 5 |
The end tag contains a slash
What is the difference between a start tag and an end tag? In this case, the start tag and the end tag differ only in that the end tag contains a slash character.
Sometimes there are other differences
However, the start tag can also contain optional attributes as discussed below. (There is also another form where the start tag and end tag are combined into something often called an empty element.)
What is an element?
It is time to learn the meaning of the jargon element, content, and
attribute.
Using widely accepted XML jargon, I will call the sequence of characters in Figure 6 an element.
An element begins with a start tag and ends with an end tag and includes everything in between.
<chap number="1">Text for Chapter 1</chap> Figure 6 |
Color coded for clarity
I used artificial color coding in Figure 6 to make it easier to refer to the different parts of the element.
(Note however, that because an XML document is maintained in plain text, the characters in an XML document do not have color properties.)
What is the content?
The characters in between the tags (rendered in green in Figure 6) constitute the content. (For more information on content, use your browser to search for the word content in The XML FAQ.)
What is an attribute?
The characters rendered in blue in Figure 6 constitute an attribute.
To recap so you will remember it
An element consists of a start tag and an end tag with the content being sandwiched in between the two tags. The content is part of the element.
May include optional attributes
The start tag may contain optional attributes. In this example, a single attribute provides the number value for the chapter. The start tag can contain any number of attributes, including none.
Tell me more about attributes
The term attribute is a commonly used term in computer science and usually has about the same meaning, regardless of whether the discussion revolves around XML, Java programming, or database management.
Attributes belong to things, or things have attributes
A chapter in a book is a thing. A chapter has a number. In this example, the chapter number is an attribute of the chapter element.
An apple has a color, red or green. An apple also has a taste, sweet or sour.
A dog has a size, small, medium, or large.
In the above statements, number, color, taste, and size are attributes. Those attributes have values like red, green, sweet, sour, small, medium, and large.
As you can see, attributes are a very common part of the world in which we live and work.
People have attributes
A person also has attributes, and each attribute has a value.
Figure 7 contains a list of some of the attributes (along with their values) that might be used to describe a person.
name="Joe" Figure 7 |
Obviously, there are many more attributes that could be used to describe a person.
The importance of an attribute depends on the context
The decision as to which of many possible attributes are important depends on the context in which the person is being considered.
Attributes for basketball players
For example, if the person is being considered in the context of being a candidate for an all male basketball team, the height, weight, and sex attributes of a person will probably be important considerations.
Attributes for programmers
On the other hand, if the person is being considered in the context of being a candidate for employment as a programmer, the height, weight, and sex attributes should not be important at all, but the training and degree attributes might be very important.
Why does XML use attributes?
Earlier in this lesson, I suggested that the most common modern use of the word rendering means to present something for human consumption. Usually, but not always, that refers to visual consumption. (My grandmother used to render fat to make soap, but that is not modern usage of the term.)
Multiple renderings for the same document
I gave an example of a newspaper that can either be rendered on newsprint paper, or can be rendered on a computer screen.
What is a rendering engine?
If the newspaper (structured document) is created and maintained as an XML document, then some sort of computer program (often referred to as a rendering engine) will probably be used to render it into the desired presentation format.
What about rendering our book?
Our book could also be rendered in a variety of different ways.
Regardless of how the book is rendered, it will probably be useful to separate and number the chapters.
The value of the number attribute for each chapter element could be used by the rendering engine to present the chapter number for a specific rendering.
Chapter numbers may be rendered differently
In some renderings, the number might appear on an otherwise blank page that begins a new chapter. This is common in printed books, but is not common in online presentations.
In a different rendering, the chapter number might appear in the upper right or left-hand corner of each page.
Separation of content from presentation
To reiterate, one of the most important characteristics of XML (as opposed to HTML) is that XML separates content from presentation.
The XML document contains information about structure and content. It does not contain presentation information (as does HTML).
Presentation of XML requires a rendering engine
The presentation of an XML document requires the use of a rendering engine of some sort to render the XML document in a particular presentation style.
IE 5.0 (and later) contains a rendering engine
As an example of rendering, IE 5.0 (and later versions)
contains a rendering engine for XML. When provided with an XML
document and no rendering instructions, IE will render the XML document
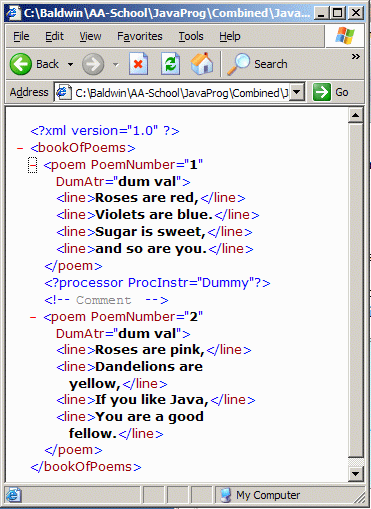
in a default format similar to that shown in Figure 8.
Figure 8 IE Rendering of XML File
This default rendering of an XML document is designed to emphasize
the tree structure of an XML document. With the IE default
rendering, the nodes in the tree can be collapsed and expanded by
clicking the - and + symbols on the left, much as you can collapse and
expand the nodes in Windows Explorer (File Manager).
When provided with an XML document and appropriate rendering instructions (such as an XSLT document), IE can transform XML data into HTML data and render it in the browser window in different formats.
What is an XSLT document?
I will have a lot to say about the Extensible Stylesheet Language (XSL), and stylesheet transformations (XSLT) in future lessons.
Attributes may be useful in rendering
Now getting back to attributes, they provide information about XML elements that may be useful to the rendering engine.
If the attribute values for an element are not important in a
particular presentation context, the rendering engine for that context
will simply ignore them. If they are important in a particular
context, the rendering engine will use them.
(The default IE rendering engine makes no use of attributes, but does display them along with the other information in the XML document.)
Elements, content, etc.
So far in this lesson, I have introduced tags, elements, content and attributes. I have discussed tags and attributes in detail. Now let's continue the discussion with particular emphasis on elements and content.
What is meant by content?
You already know about start tags and end tags.
You also know that an element consists of a start tag (with
optional attributes), an end tag, and the content
in between as shown in Figure 9.
<chapter number="1">Content for Chapter 1</chapter> Figure 9 |
In Figure 9, the optional attribute is colored blue and the content
is colored green.
(Recall however, that because an XML document is maintained in plain text, the characters in an XML document do not have color properties. I used color in this lesson simply to aid in the explanation.)
Elements can be nested
Elements can be nested inside other elements in the construction of the XML document as shown in Figure 10.
<book> Figure 10 |
Color coding and indentation
In Figure 10, the tags belonging to the book element are shown in blue while the tags belonging to the chapter elements are shown in green.
I also provided artificial indentation to make it easier to see that two chapter elements are nested inside a single book element.
Indentation is common
Such indentation is common in the presentation of raw XML data for human consumption. For example, the default rendering of an XML document by IE is an indented tree structure as shown in Figure 8.
Identify the elements
The book element consists of its start tag, its end tag, and everything in between (including nested elements), as shown in Figure 11.
<book> Figure 11 |
Each chapter element consists of its start tag, its end tag, and everything in between, as shown in Figure 12.
<chapter number="1"> Figure 12 |
Content of the book element
In this case, the two chapter elements form the content of the book element.
So, what is an element?
The element is the fundamental unit of information in an XML document. Most XML processing programs (such as rendering engines) depend on this fundamental unit of information in order to do their job.
An XML document is an element
The entire XML document is an element. As shown in Listing 2, the entire XML document consists of the book element. It is often referred to as the root element.
To be of much use, an XML document must have other elements nested inside the root element. For example, a nested element can define some type of information, such as chapter in our book example. Other possibilities would be table elements and appendix elements.
Meta information
Through the use of attributes, the element often defines information about the information provided by the XML document (sometimes referred to as meta information).
In our book example, the number attribute provides the chapter number for each of the chapter elements. In effect, the chapter number is information about the information contained in the chapter.
The content
Sandwiched in between the start tag and the end tag of an element, we find the information (content) that the XML document is designed to convey.
So, what are elements good for?
By using a well-defined structure (based on XML elements) to create and maintain your document, you make it much easier to write computer programs that can be used to render, and otherwise process your document.
Writing programs to process XML documents
At some point, you might want to visit one of my earlier articles
entitled "What is SAX, Part 1."
(You will find a link to that article at www.dickbaldwin.com.)
That article describes how to write computer programs (using the Java programming language) that decompose an XML document into its elements for some useful purpose.
In those articles, I explain that SAX supports an event-based approach to XML document processing. (If you have a background in event-driven programming, such as Java or Visual Basic, you will like the SAX approach.)
Parsing events
An event-based approach reports parsing events (such as the start and end of elements) to the program using callbacks. The program implements and registers event handlers (callback methods) for the different events.
Code in the event handlers is designed to achieve the objective of the program.
Not critical to understanding XML
I will have a great deal more to say about processing XML documents using SAX in future lessons. I realize that a discussion of event-driven programming for the processing of XML documents might not be classified as "information for Getting Started with JAXP." It is not even critical for an understanding of XML.
However, it is a good way to illustrate the benefits provided by XML elements. Don't worry too much about SAX at this at this point. Just keep studying, and at some point in the future, it will fall into place.
What we have learned so far?
So far in this lesson, I have introduced you to tags, elements, content, and attributes. I have discussed tags, attributes, and elements in detail. Now, I will discuss content in detail.
What is content?
Of the four terms mentioned above, content is the easy one. Sandwiched in between the start tag and the end tag of an element, we find the information (content) that the XML document is designed to convey.
This is where we put the information for which the document was created.
An XML newspaper
For example, if the XML document is being used for creation and maintenance of material for a newspaper, the content is the news.
A Java programming textbook
If the XML document is being used for creation and maintenance of a Java programming textbook, the content contains the information about Java programming that we want to present to the student.
Tags, attributes, and elements define structure
The content is the raw information. The tags, attributes, and elements define the structure into which we insert that information.
Why do we need structure?
One of the primary objectives of XML is to separate content from presentation.
If we insert the raw material as content into a structure defined by the tags, elements, and attributes, then that raw material can be presented (rendered) in a variety of ways. It can also be searched in a variety of ways that can produce results that are more meaningful than simple keyword searches.
Same content, different renderings
For example, an XML document can be used to represent a newspaper.
Then that document can be presented as an ordinary hard copy newspaper by printing the content on newsprint in a format defined by the structure. Typically, we would use a rendering engine designed for that purpose.
The same XML document can be used to present the same information in a completely different rendering on a computer screen. Again, we would probably use a rendering engine designed for that purpose.
Rendering engine formats the content
In both cases, the rendering engine would examine the structure defined by the tags, elements, and attributes and would then format and present the news (content) in a format appropriate for the presentation media being used.
What does the future hold for XML?
Obviously, I believe that XML has a very bright future. Otherwise, I wouldn't be making the kind of substantial investment in time and energy that I am making in order to understand XML.
I base this belief on the fact that many large companies, including Microsoft and IBM have adopted XML as an important part of their future.
XML will grease the skids of electronic commerce
For example, here are some of the things that Simon Phipps, IBM's
chief XML and Java evangelist had to say in his keynote speech at the Software
Development East conference a few years ago.
"Because it allows companies to share information with customers or business partners without first negotiating technical details, Extensible Markup Language (XML) will grease the skids of electronic business and become the assumed data format at the end of 2001."
XML provides vendor independence
Phipps went on to say:
"Other successful Internet technologies let people run their systems without having to take into account another company's own computer systems, notably TCP/IP for networking, Java for programming, and Web browsers for content delivery. XML fills the data formatting piece of the puzzle."
"These technologies do not create dependencies. It means you can build solutions that are completely agnostic about the platforms and software that you use."
XML can reduce system costs
In the speech, entitled "Escaping Entropy Death" Phipps noted that users are reaching the point where the cost of simply owning some systems is exceeding the value they provide.
"The key benefit to IT managers that adopt XML and other non-proprietary standards is that they will greatly reduce the cost of maintaining a computer's systems and will allow them to extend existing systems."
"In the next decade, you can't just ask when can you have [a new application]. You also have to ask how much will it cost to own."
No more vendor-imposed standards
According to Phipps:
"The solution, interestingly enough, is not constant innovation. You have to redeem the best of the parts you have and combine them with the best of the future."
Phipps contended that the IT industry has moved on from the era of "vendor-imposed standards."
This is an interesting observation by a representative from IBM. I grew up on computers during an era when IBM was the vendor who imposed the standards.
Some would say that the role of imposing standards has now been assumed by Microsoft (much to the dismay of IBM management).
What about Microsoft and XML?
Microsoft is making a huge investment in XML. As mentioned earlier, Microsoft's IE browser currently supports XML documents, XSL stylesheets, and XSL transforms.
(You can find links to several articles that I have previously written discussing the rendering of XML documents using XSLT at www.DickBaldwin.com.)
In addition, many aspects of Microsoft's latest MS.NET product
depend extensively
on XML.
The XSL Debugger from Microsoft
XSL is complex (much more complex than XML). Designing an XSL stylesheet, to be used by a rendering engine to properly render an XML document, can be a daunting task.
To help us in that regard, Microsoft has developed an XSL debugger, and has made it freely available for downloading. As of the date of this writing, the debugger can be downloaded from http://www.vbxml.com/xsldebugger/. I will discuss the use of this debugger in future lessons that discuss the creation of XML processing programs using XSLT and JAXP.
Check out XML in MS Word
If you happen to have a copy of Microsoft Word around, use it to create a simple HTML file. Load that file into your HTML browser and view the source. When you do, you will find XML appearing at various locations in the control information created by Word in that HTML document.
What we have learned so far?
So far in this lesson, I have discussed tags, elements, content, and attributes in detail. I have also presented a short sales pitch designed to convince you of the importance of XML.
Now we are ready to move on to a new set of topics: valid documents, well-formed documents, and the DTD.
What is a DTD?
The quotation in Figure 13 was extracted from The XML FAQ.
| "A DTD is usually a file (or several files to be used
together) which contains a formal definition of a particular type of
document. This sets out what names can be used for elements, where
they may occur, and how they all fit together. For example, if you want
a document type to describe <LIST>s which contain <ITEM>s,
part of your DTD would contain something like
<!ELEMENT item (#pcdata)> <!ELEMENT list (item)+> This defines items containing text, and lists containing items. It's a formal language which lets processors automatically parse a document and identify where every element comes and how they relate to each other, so that stylesheets, navigators, browsers, search engines, databases, printing routines, and other applications can be used."Figure 13 |
DTDs can be very complicated
I included the above quotation to emphasize one important point – DTDs are, or can be, very complicated.
The reality is that the creation of a DTD of any significance is a very complex task.
Don't panic
However, despite their complexity, many of you will never need to worry about having to create DTDs for the following two reasons:
The three amigos
An XML document has two very close friends, one of which is optional.
I'm going to refer to them as three files just so I will have something to call them (but they don't have to be separate physical files).
One file contains the content
One file contains the content of the document (words, pictures, etc.). This is the part that the author wants to expose to the client. This file contains the XML code that I have been discussing up to this point.
This is the file that is composed of elements, having start tags, end tags, attributes, and content. For convenience, the file name often has an extension of xml, although that is not a requirement.
A second file contains the DTD
A second file contains the DTD, which meets the above definition
that was
extracted from the FAQ.
This file
is optional.
(Note that a modern alternative to the DTD is often called a schema. A schema, when it is available, serves the same purpose as a DTD, but is often more powerful. I will have more to say about schema in future lessons.)
A third file contains a stylesheet
A third file contains a stylesheet, which establishes how the content (that optionally conforms to the DTD) is to be rendered on the output device for a particular application.
This file defines how the author wants the material to be presented to the client.
Rendering the XML document
Different stylesheets are often used with the same XML data to cause that data to be rendered in different ways. For example a tag with an attribute of "red" might cause something to be presented bright red according to one stylesheet and dull red according to another stylesheet. (It might even be presented as some shade of green according to still another stylesheet, but that wouldn't be a very good design.)
DTD is optional, stylesheet is not
With XML, the DTD is optional but the stylesheet (or some processing mechanism that substitutes for a stylesheet) is required. At least that is true if the XML document is ever to be rendered for the benefit of a client.
Something must provide rendering specifications
Remember, XML separates content from presentation.
There is no presentation information in the XML document itself.
Therefore, rendering specifications must be provided to make it possible to render the content of the XML document in the manner intended by the author.
A stylesheet is typical, but not required
Typically, the rendering specifications are contained in a stylesheet. The stylesheet is used by a rendering engine to render the XML document according to the specifications in the stylesheet.
However, it is possible that the specifications could be hard-coded into a program written specifically for the purpose of rendering the XML document. In that case, a stylesheet might not be required.
Rendering XML with XSL and MS IE
As mentioned earlier, I have published several articles that deal with using IE to render XML using stylesheets written in XSL. You will find links to those articles at www.DickBaldwin.com.
Now back to the DTD.
A DTD can be very complex
Again, according to The XML FAQ,
| "... the design and construction of a DTD can be a complex
and non-trivial task, so XML has been designed so it can be used either
with or without a DTD. DTDless operation means
you can invent markup without having to define it formally.
To make this work, a DTDless file in effect 'defines’ its own markup, informally, by the existence and location of elements where you create them. But when an XML application such as a browser encounters a DTDless file, it needs to be able to understand the document structure as it reads it, because it has no DTD to tell it what to expect, so some changes have been made to the rules." Figure 14 |
What does this really mean?
It means that it is possible to create and process an XML document without the requirement for a DTD. A little later, I will discuss this possibility in connection with the term well-formed.
In the meantime...
You don't always have the luxury of avoiding the DTD. In some situations, you may be required to create an XML document that meets specifications that someone else has defined.
Hopefully, a DTD will be available
Ideally, in those cases, the person who defined the specifications has also created a DTD and can provide it to you for your use.
A valid document
Here is a new term -- a valid XML document.
In the normal sense of the word, if something is not valid, that usually means that it is not any good. However, that is not the case for XML.
An invalid XML document can be a good XML document
An invalid XML document can be a perfectly good and useful XML document. A very large percentage of useful XML documents are not valid XML documents.
So, what is a valid XML document?
Drum roll please!!! Without further delay, a valid XML document is one that conforms to an existing DTD in every respect.
For example...
Unless the DTD allows an element with the name "color", an XML document containing an element with that name is not valid according to that DTD (but it might be valid according to some other DTD).
Validity is not a requirement of XML
Many very useful XML documents are not valid, simply because they were not constructed according to an existing DTD.
To make a long story short, validation against a DTD can often be very useful, but may not be required.
A well-formed document
Here is another new term -- a well-formed document.
The concept of being well-formed was introduced as a requirement of XML, to deal with the situation where a DTD is not available (an invalid document).
Again, according to The XML FAQ,
| "For example, HTML's <IMG> element is defined as
'EMPTY': it doesn't have an end-tag. Without a DTD, an XML application
would have no way to know whether or not to expect an end-tag for an
element, so the concept of 'well-formed' has been
introduced.
This makes the start and end of every element, and the occurrence of EMPTY elements completely unambiguous." Figure 15 |
What is an HTML <IMG> tag?
Although you may not know anything about the HTML <IMG> tag, you do know about start tags and end tags from previous discussion in this article.
Although HTML is related to XML (a distant cousin that combines content and presentation in the same document), HTML documents are not required to be well-formed.
The quotation in Figure 15 refers to the use of a start tag (<IMG>) in HTML that doesn't require an end tag. If used in that manner in an XML document, the document would not be well-formed.
All XML documents must be well-formed
XML documents need not be valid. However:
All XML documents must be well-formed.
What does it mean to be well-formed?
For a rigorous definition of a well-formed document, see http://www.w3.org/TR/2000/REC-xml-20001006#sec-well-formed.
From a somewhat less rigorous viewpoint, XML documents must adhere to the following rules to be well-formed.
What is character data?
Although not rigorously true, for purposes of this discussion, let's just say that the content that we discussed in an earlier section comprises character data.
Other requirements
All attribute values must be in quotes (apostrophes or double quotes). You already know about attributes. I discussed them earlier in this lesson.
You can surround the value with apostrophes (single quotes) if the attribute value contains a double quote. Conversely, an attribute value that is surrounded by double quotes can contain apostrophes.
Dealing with empty elements
We must also deal with empty elements. Empty elements are those that don't contain any character data. You can deal with empty elements by writing them in either of the two ways shown in Figure 16.
| <book></book>
<book/> Figure 16 |
You will recognize the format of the first line as simply writing a start tag followed immediately by an end tag with nothing in between. The format of the second line in Figure 16 has a slash at the end of the word book.
The second format is preferable
This is the first time in this lesson that I have mentioned the second format, which is actually preferable.
One reason the second format is preferable is that because of word wrap and other causes, you could end up with the first format in Figure 16 being converted to that shown in Figure 17.
| <book>
</book> Figure 17 |
Really not empty
Once this happens, although the element may look empty to you, it really isn't empty. Rather it contains whatever characters are used by that platform to represent a newline character sequence.
Typically a newline is either a carriage return character, a line feed character, or a combination of the two. While these characters are not visible, their presence will cause an element to be not empty.
If an element is supposed to be empty, but it is not really empty, this can cause problems when the XML file is processed.
The preferred approach
So, to reiterate, the preferred approach for representing an empty element is as shown by the second line in Figure 16.
Empty element can contain attributes
Note that an empty element can contain one or more attributes inside the start tag, as shown in by the example in Figure 18.
| <book
author="baldwin" price="$9.95" /> Figure 18 |
Again, note the slash character at the end.
Another rule: No markup characters are allowed
For a document to be well-formed, it must not have markup characters (<, >, or &) in the text data.
What is a markup character?
Since the < character represents the beginning of a new tag, if it were included in the text data, it would cause the processor to become confused. Similarly, because the > character represents the end of a tag, inclusion of that character in the text data can also cause problems. The solution to this problem (entities, as described below) also makes it necessary to exclude the & character from the text data.
The solution
If you need for your text to include the < character, the > character, or the & character, you can represent them using < > and & instead. (Note that I purposely omitted the use of a comma in this list of entities to avoid having a comma become confused with the required syntax for an entity, which always begins with an ampersand and always ends with a semicolon.)
Entities
According to the prevailing jargon, these are called entities. You insert them into your text in place of the prohibited characters.
Entities always start with an ampersand character and end with a
semicolon. It is that combination of characters that the
processor uses to distinguish them from ordinary text.
Other common entities
Although it may not be necessary for well-formedness, it is also
common practice to use an entity to represent the quotation mark
character (") by the entity ". It is also
possible to use an entity to
represent many other characters, including characters that don't appear
on
a standard English-language keyboard.
Valid XML files are those which have (or refer to) a DTD and which conform to the DTD in all respects.
XML files must be well-formed, but there is no requirement for them to be valid. Therefore, a DTD is not required, in which case validity is impossible to establish.
If XML documents do have or refer to a DTD, they must conform to it, which makes them valid.
Why use a DTD if it is not required?
There are several reasons to use a DTD, in spite of the fact that XML doesn't require one.
Enforcing format specifications
Suppose, for example, that you have been charged with publishing a weekly newsletter, and you intend to produce the newsletter as an XML file.
Suppose also that you occasionally have a guest editor who produces the newsletter on your behalf.
Establish format specifications
You will probably establish a set of format specifications for your newsletter and you will need to publish those specifications for the benefit of the guest editors.
No guarantee of compliance
However, simply publishing a document containing format specifications does not ensure that the guest editors will comply with the specifications.
Use a DTD to enforce format specifications
You can enforce the format specifications by also establishing a DTD that matches the specifications.
Then, if either you, or one of your guest editors produces an XML document that doesn't meet the specifications, the XML processor that you use to render your newsletter into its final form will notify you that the document is not valid.
Improved parser diagnostic data
Another reason that I have found a DTD to be useful is the following.
I am occasionally called upon to write a Java program that will parse and process an XML document in some fashion.
My experience is that the parsers that I have used are much more effective in identifying XML structural problems when the XML document has a DTD than when it doesn't.
By this I mean that often the diagnostic information provided by the parser is more helpful when the XML document has a DTD.
This tends to make it easier to repair the document because a validating parser does a better job of isolating the problem.
More than you wanted to know
And that is probably more than you ever wanted to know about
XML. Now it's time to terminate this review of XML and get to the
meat of this series of tutorial lessons - using Java JAXP to process
XML documents.
Having taken a very long detour to help the XML newcomers catch up with everyone else, I will now get back on track and begin discussing JAXP.
XML by itself isn't very useful
In reality, an XML document is simply a text document constructed
according to a certain set of rules and containing information that the
author of the document may want to expose to a client. (The
client
could be a human, or could be another computer.)
Taken by itself, the XML document isn't worth much, particularly in
those cases where the client is a human. To be very useful, the
XML document must be combined with a program that is designed to do
something useful with that document. In other words, in order for
an XML document to be useful to you, you need access to a program that
can process that document to your satisfaction.
DOM and SAX
Brief introduction to DOM
An XML document can be viewed as a tree structure where the elements
constitute the nodes in the tree. Some of the nodes have child
nodes and some do not.
(Usually those nodes that have no children are referred to as leaf nodes. This notation is based on the concept of a physical tree where the root subdivides into trunk, limbs, branches, twigs, and finally leaves. However, the leaves don't subdivide. Leaves on a physical tree don't have children.)
An example of a tree structure
Referring back to the XML document in Listing 1, the element named book
could be viewed as the root of a tree structure. It has two
children, which are the elements named chap. Each of the
elements named chap has a child, which is the text shown in Listing
1. The text forms the leaves of this tree.
A tree structure in memory
A DOM parser can be used to create a tree structure in memory, which
represents an XML document. In Java, that tree structure is
encapsulated in an object of the interface type Document.
Document declares numerous methods. Document is
also a subinterface of Node, and inherits many method
declarations from Node.
Many operations are possible
Given an object of type Document, there are many methods
that can be invoked on the object to perform a variety of
operations. For example, it is possible to move nodes from one
location in the tree to another location in the tree, thus rearranging
the structure of the XML document represented by the Document
object. It is also possible to delete nodes, and to insert new
nodes. As you will see in the sample program in this lesson, it
is also possible to recursively traverse the
tree, extracting information about the nodes along the way.
I will show you ...
In this lesson, I will show you how to:
The Document object represents the original XML file and the
DOM tree is not modified in this example. The final XML file
represents the unmodified Document object, which represents the
original XML file. Therefore, the final XML file will be
functionally equivalent to the original XML file.
Nothing fancy intended
This sample program is not intended to do anything fancy.
Rather, it is intended simply to help you take the first small step
into the fascinating world of Java, JAXP, and XML.
(Note that the declaration may also contain additional information that is not included in this simple XML document.)
<?xml version="1.0"?> |
<bookOfPoems> |
<bookOfPoems> |
<poem PoemNumber="1" DumAtr="dum val"> |
<poem PoemNumber="2" DumAtr="dum val"> |
<bookOfPoems> |
It is important to note that although I have presented this XML document with different colors to identify the different parts, there is no color in an actual XML document. Recall from the earlier discussion that one of the most important aspects of XML documents is that they exist in plain text, which doesn't include attributes such as boldface, Italics, underline, or color. This makes XML documents easily transportable among different kinds of computers and different operating systems.The class named Dom02
import javax.xml.parsers.DocumentBuilderFactory; |
"Defines a factory API that enables applications to obtain a parser that produces DOM object trees from XML documents."The DocumentBuilderFactory class extends Object, and defines about fifteen methods, one of which is a static method named newInstance. As is often the case with factory objects, the newInstance method is used to create an object of the class.
(Note that although the quotation from Sun in the next section uses the terminology DocumentBuilderFactory.newDocumentBuilder method, the newDocumentBuilder method is an instance method and is not a static or class method.)The DocumentBuilder Class
"Defines the API to obtain DOM Document instances from an XML document. Using this class, an application programmer can obtain a Document from XML.This class also extends Object, and defines about ten methods, which include several overloaded versions of the parse instance method. When the parse method is invoked and passed an input source containing XML, the method returns a Document object (DOM tree) that represents the XML.
An instance of this class can be obtained from the DocumentBuilderFactory.newDocumentBuilder method. Once an instance of this class is obtained, XML can be parsed from a variety of input sources. These input sources are InputStreams, Files, URLs, and SAX InputSources."
(Because Document extends Node, that object could also be treated as type Node when appropriate.)Don't know and don't care
"The Document interface represents the entire HTML or XML document. Conceptually, it is the root of the document tree, and provides the primary access to the document's data."Sun describes a Node as follows:
"The Node interface is the primary datatype for the entire Document Object Model. It represents a single node in the document tree. While all objects implementing the Node interface expose methods for dealing with children, not all objects implementing the Node interface may have children. For example, Text nodes may not have children, and adding children to such nodes results in a DOMException being raised."Methods of Document and Node
public class Dom02{
|
try{
|
(Note that the validating and namespaceAware properties are false by default, so inclusion of the corresponding statement in Listing 11 didn't accomplish anything, other than to illustrate the location and use of these methods.)Get a DocumentBuilder (parser) object
DocumentBuilder builder = |
(Thus, it would have been equally appropriate to save the object's reference in a variable named parser.)Create a Document object
Document document = builder.parse( |
new Dom02Writer(argv[1]). |
public class Dom02Writer {
|
public void writeXmlFile(Document document){
|
"The Document interface represents the entire ... XML document. Conceptually, it is the root of the document tree, ..."Recall also that when discussing a Document object, I told you
"Because Document extends Node, that object could also be treated as type Node when appropriate."We're now going to put all of that to the test. In effect, the Document object is a Node, which represents the root node of the DOM tree, and we can pass its reference to the method named writeNode, which requires an incoming parameter of type Node.
(Typically at a time like this, I would tell you that if you don't understand recursion, you could visit my web site where you will find tutorial lessons that explain recursion. However, I have just realized that despite the fact that I have published several hundred lessons on OOP and Java, I have never published a lesson that concentrates on the implementation of recursion in Java. Therefore, the best that I can do at this point is to tell you to fire up your Google search engine and search for the keywords Java and recursion. You will probably find many sites that deal with recursion in Java.)The writeNode method
public void writeNode(Node node) {
|
int type = node.getNodeType(); |
switch (type) {
|
"This is a convenience attribute that allows direct access to the child node that is the root element of the document. For HTML documents, this is the element with the tagName "HTML"."For the XML file being processed in this example, this will be the element named bookOfPoems.
(Although I'm not certain, I suspect that the documentation author intended to say convenience method instead of convenience attribute.)An object of interface type Element
"The Element interface represents an element in an HTML or XML document. Elements may have attributes associated with them; since the Element interface inherits from Node, the generic Node interface attribute attributes may be used to retrieve the set of all attributes for an element. There are methods on the Element interface to retrieve either an Attr object by name or an attribute value by name. In XML, where an attribute value may contain entity references, an Attr object should be retrieved to examine the possibly fairly complex sub-tree representing the attribute value."The interface declares about fifteen methods, which make it possible to perform various operations on an Element object.
Important: The statement that reads out.flush and all of the remaining code in this method will not be executed until the recursive call to writeNode() returns.In effect, the code for the DOCUMENT_NODE case in the writeNode method (Listing 19) simply gets the object in the DOM tree corresponding to the root element in the XML document and passes it recursively to the writeNode method. This causes the information corresponding to the root element to be written to the output file.
Listing 20 shows the beginning of the code in the switch case where the node type is ELEMENT_NODE.
case Node.ELEMENT_NODE: {
|
"The Attr interface represents an attribute in an Element object. Typically the allowable values for the attribute are defined in a document type definition.Process the attributes, if any
Attr objects inherit the Node interface, but since they are not actually child nodes of the element they describe, the DOM does not consider them part of the document tree. Thus, the Node attributes parentNode, previousSibling, and nextSibling have a null value for Attr objects. The DOM takes the view that attributes are properties of elements rather than having a separate identity from the elements they are associated with; this should make it more efficient to implement such features as default attributes associated with all elements of a given type. Furthermore, Attr nodes may not be immediate children of a DocumentFragment. However, they can be associated with Element nodes contained within a DocumentFragment. In short, users and implementors of the DOM need to be aware that Attr nodes have some things in common with other objects inheriting the Node interface, but they also are quite distinct."
//Get attributes into an array |
NodeList children = node.getChildNodes(); |
case Node.ENTITY_REFERENCE_NODE:{
|
case Node.CDATA_SECTION_NODE: |
case Node.PROCESSING_INSTRUCTION_NODE:{
|
//Now write the end tag for element nodes |
private String strToXML(String s) {
|
private Attr[] getAttrArray( |
"Objects implementing the NamedNodeMap interface are used to represent collections of nodes that can be accessed by name. ... Objects contained in an object implementing NamedNodeMap may also be accessed by an ordinal index, but this is simply to allow convenient enumeration of the contents of a NamedNodeMap, and does not imply that the DOM specifies an order to these Nodes."A NamedNodeMap object provides several methods, which can be used to
I encourage you to copy the code from Listings 28, 29, and 30 into your text editor, compile it, and execute it. Experiment with it, making changes, and observing the results of your changes.
In this first lesson on Java JAXP, I began by providing a brief description of JAXP and XML. Then I reviewed the salient aspects of XML for those who need to catch up on XML technology.
Following that, I provided a brief discussion of the Document Object
Model (DOM) and the Simple API for XML (SAX). I discussed how a
DOM object represents an XML document as a tree structure in
memory. I explained that once you have the tree structure in
memory, there are many operations that you can perform to create,
manipulate, and/or modify the structure. Then you can convert
that modified tree structure into a new XML document.
Using two sample Java class files, I showed you how to:
What I did not do in this lesson, (but will do in a future
lesson), is to show you how to modify the tree structure for
purposes of creating a modified XML file.
The things that you learned about traversing the tree structure and
getting information about each node in the tree will serve you well in
the future. However, if all you need to do is to write an output
XML file that represents the DOM, there is an easier way to do that
using Extensible Stylesheet Language Transformations (XSLT). That
will be the primary topic of the next lesson.
In this lesson, I didn't show you how to write code that produces
meaningful output in the event of a parser error or exception. I
will also cover that topic in the next lesson.
/*File Dom02.java |
/*File Dom02Writer.java |
<?xml version="1.0"?> |
Copyright 2003, Richard G. Baldwin. Reproduction in whole or in part in any form or medium without express written permission from Richard Baldwin is prohibited.
Richard has participated in numerous consulting projects, and he frequently provides onsite training at the high-tech companies located in and around Austin, Texas. He is the author of Baldwin's Programming Tutorials, which has gained a worldwide following among experienced and aspiring programmers. He has also published articles in JavaPro magazine.
Richard holds an MSEE degree from Southern Methodist University and has many years of experience in the application of computer technology to real-world problems.
-end-