We first employed the Viola-Jones toolbox from Matlab to capture the face for each frame, but we found out both the false positives and false negatives are pretty high. Then we found similar problems while applying HOG feature detection for the upper body. However, there is a large overlap between the success rate in terms of frames for those two methods, that is, when face and upper body are detected in one region at the same time, that region is highly likely to contain a person; on the other hand, we understand that false positive are much harder to eliminate in the following denoising process while false negatives can be filled in by predicting the movements of the human body. As a result, we employed the algorithm that detect the face and human body at the same time, and we select the pair of y coordinates from both detections that are within a certain range, (assuming the person is jumping upright), then we simply disregard all the other detections.
Both Viola-Jones and HOG human body detection have adjustable threshold parameters to detect how strictly we recognize an object as a face or human body. We found out that higher threshold tends to produce better results if the background of the input is relatively complicated, and lower threshold tend to produce better results if the background of the input is clear and simple. For now, our algorithm has taken the threshold parameter as an input, we are planning on internalizing it so that the algorithm can automatically set the threshold based on the condition of the image.
2. denoising:
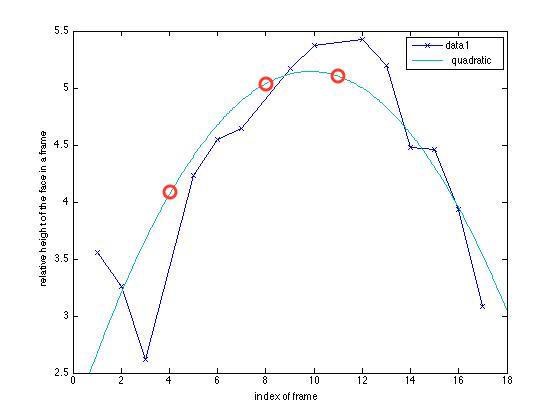
Denoising process involves correcting false positive and false negatives errors introduced by detection. Approaches to reduce false positives errors have been talked about in the previous section. To deal with false negatives, based on the assumption that jumping height changes quadratically with time we used quadratic regression curve to fit the height-time curve. If not all the faces are detected in a frame, we would use points predicted by the regression model as the height of the face in that frame, as illustrated by Figure. 1. This way, we will be able to deduce the relative position of the face in each frame where the algorithms fails to locate the human face. We can also ensure that all the data points are available for the final selection process.
Fitting
Fitting missing data points at frames 4, 8, and 11
3. calibrate with reference to horizon:
The problem might occur that hand and camera shakes cause a person to be high in a frame, but this frame in fact is not where the person is jumping the highest. To capture the point where the person is truly at the highest point of his trajectory, we not only track the height of a person in the image, not also his absolute height, as measured with reference to the horizon. When the program runs, it performs constant background subtraction. If it is detected that background from frame to frame changes above a pre-selected threshold, which indicates that the camera is not fixed properly, the program will use the absolute height instead of the relative height in the image.
4. multiple jumpers:
In the case that more than one person jumps, at this stage we have to ask the user to specify how many people jump at the same time. Assuming that when a person jumps, his/her motion in the horizontal direction is small. Then, based on every person’s initial coordinates, we take face recognized at roughly the same horizontal position as the face that belongs to the same person. In this way, we separate each person’s jumping trajectory and will be able to track individually.
5. selection:
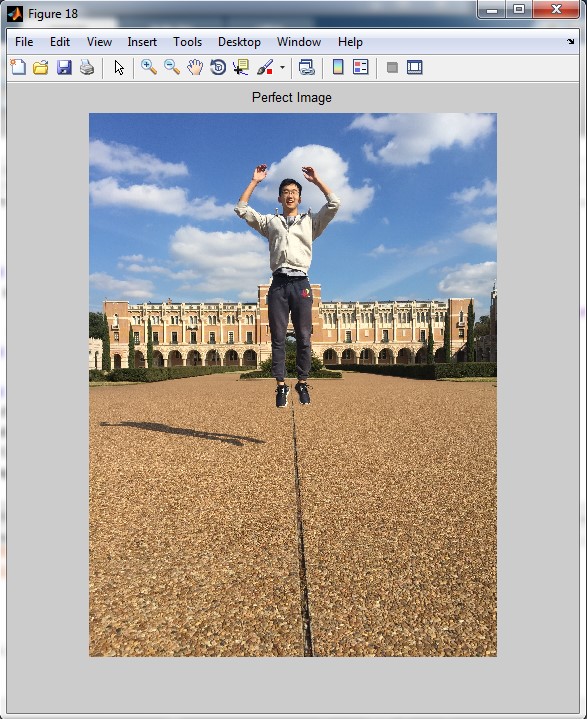
Once the previous steps are achieved, the selection process is easy: the algorithms will selected the index of the frame where the distance between the reference point and face is maximum. Figure. 3 illustrates the selected optimal picture when the program runs on the photo stream shown by Figure. 2.
Input photo stream
Input photo stream
Perfect moment
Best frame selected.
Vii. results:
Judging from our demonstrations during the design process and the presentation session, we conclude that our application is able to fulfill its designed purpose of detecting one person with relatively short runtime (roughly 30 seconds for this prototype) . It is able to catch the frame that is within best 3% of the actual frames. For multiple people detection, the algorithm works relatively after we specify how many people are jumping, and it can catch the frame within best 10% of actual frames.
Viii. future work:
We have successfully constructed this algorithm to capture the perfect moment for a single person. Now we are working to enable this application to capture multiple people jumping at the same time. We are trying to tackle the following difficulties in future development:
The algorithm needs to know how many faces to track and this input metrics is manually given right now. We will need work towards auto detection.
Multiple people might not jump at the same time, thus creating situations where the peaks of each projectile do not occur in the same frame. We are considering algorithms that could find the best possible relative position of faces within each frame.
As specified above, we have to set the threshold of the detection model as an input based on the complexity of the back ground. In the future, we are looking to let the algorithm detecting the complexity of the back ground and decide the threshold on its own.
We have designed our GUI for an IOS application already, and we found out open source packages of both Viola Jones algorithms and HOG feature detection algorithms online, so we are planning on integrating them together as a real smartphone application. 30 seconds are clearly not user-friendly enough, so we are definitely aiming for instant generation of results.
After talking with some audiences during the poster presentation, we are considering the possibility of real-time processing including a level of parallel computing and deep learning techniques for detecting faces more quickly.