

| << Chapter < Page | Chapter >> Page > |

Appendix 3 contains listings of FFTs with vectorized loops. The input and output of the FFTs is in interleaved format, but thecomputation of the inner loops is performed on split format data. At the leaves of the transform there are no loops, so the computation falls back to scalararithmetic.
[link] summarizes the performance of the listings in Appendix 3 . Interestingly, the radix-2 FFT is faster than both the conjugate-pair and ordinary split-radix algorithms until size 4096transforms, and this is due to the conjugate-pair and split-radix algorithms being more complicated at the leaves of the computation. The radix-2 algorithmonly has to deal with one size of sub-transform at the leaves, but the split-radix algorithms have to handle special cases for two sizes, andfurthermore, a larger proportion of the computation takes place at the leaves with the split-radix algorithms. The conjugate-pair algorithm is again slowerthan the ordinary split-radix algorithm, which can (again) be attributed to the compiler's relatively degenerate code output when computing complexmultiplication with a conjugate.
Overall, performance improves with the use of explicit vector parallelism, but still falls short of the state of the art. The next section characterizes the remaining performance bottlenecks.
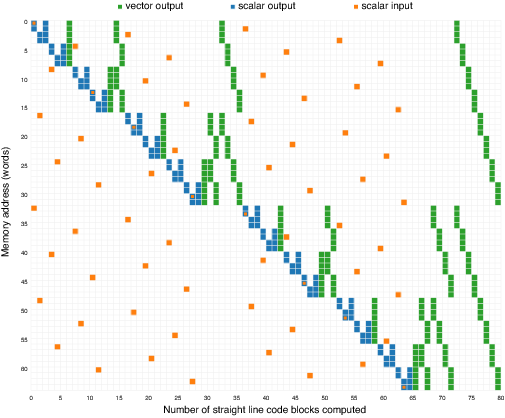
The memory access patterns of an FFT are the biggest obstacle to performance on modern microprocessors. To illustrate this point, [link] visualizes the memory accesses of each straight line block of code in a size 64 radix-2 DIT FFT (the source code of whichis provided in Appendix 3 ).
The vertical axis of [link] is memory. Because the diagram depicts a size 64 transform there are 64 rows, each corresponding to a complex word in memory. Because thetransform is out-of-place, there are input and output arrays for the data. The input array contains the data “in time”, while the output array contains the result “infrequency”. Rather than show 128 rows – 64 for the input and 64 for the output – the input array's address space has been aliased over the output array'saddress space, where the orange code indicates an access to the input array and the green and blue codes for accesses to the output array.
Each column along the horizontal axis represents the memory accesses sampled at each kernel (i.e., butterfly) of the computation, which are all straight line blocks of code. The first column shows two orange and oneblue memory operations, and these correspond to a radix-2 computation at the leaves reading two elements from the input data, and writing twoelements into the output array. The second column shows a similar radix-2 computation at the leaves: two elements of data are read from the input at addresses 18 and 48, the size 2DFT computed, and the results written to the output array at addresses 2 and 3.
There are columns that do not indicate accesses to the input array, and these are the blocks that are not at the leaves of the computation. They load data from somelocations in the output, performing the computation, and store the data back to the same locations in the output array.
There are two problems that [link] illustrates. The first is that the accesses to the input array – the samples “in time" – are indeed very decimated, as might be expected with a decimation-in-time algorithm. Second, it can be observed that the leaves of the computation are rather inefficient, because there are large numbers ofstraight line blocks of code performing scalar memory accesses, and no loops of more than a few iterations (i.e., the leaves of the computation are not taking advantage of the machine's SIMD capability).
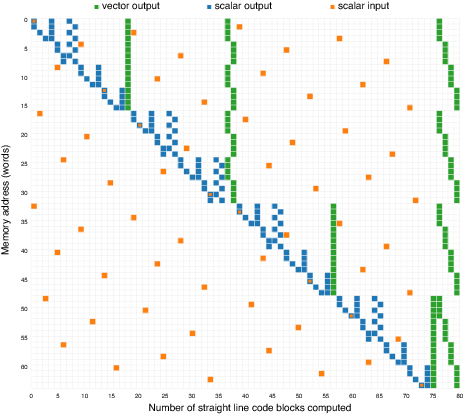
[link] in the previous section showed that the vectorized radix-2 FFT was faster than the split-radix algorithms up to size4096 transforms; a comparison between [link] and [link] helps explain this phenomenon. The split-radix algorithm spends more time computing the leaves of the computation (blue), so despite thesplit-radix algorithms being more efficient in the inner loops of SIMD computation, the performance has been held back by higher proportion of verysmall straight line blocks of code (corresponding to sub-transforms smaller than size 4) performing scalar memory accesses at the leaves of thecomputation.
Because the addresses of memory operations at the leaves are a function of variables passed on the stack, it is very difficult for a hardware prefetchunit to keep these leaves supplied with data, and thus memory latency becomes an issue. In later chapters, it is shown that increasing the size of the basecases at the leaves improves performance.
Notification Switch
Would you like to follow the 'Computing the fast fourier transform on simd microprocessors' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|