

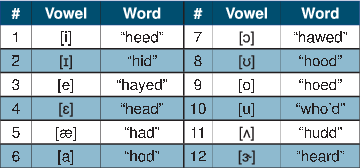
| << Chapter < Page | Chapter >> Page > |
Adrian A. Galindo Experimental Methodology, Conclusions, and Future Work
We now turn our attention to the work that went into testing our model to ensure it worked as designed.
In order to test if our system works we had to ensure that the algorithm would produce the correct result (allow, deny) regardless of which recording of the template speaker or the two intruders we used.
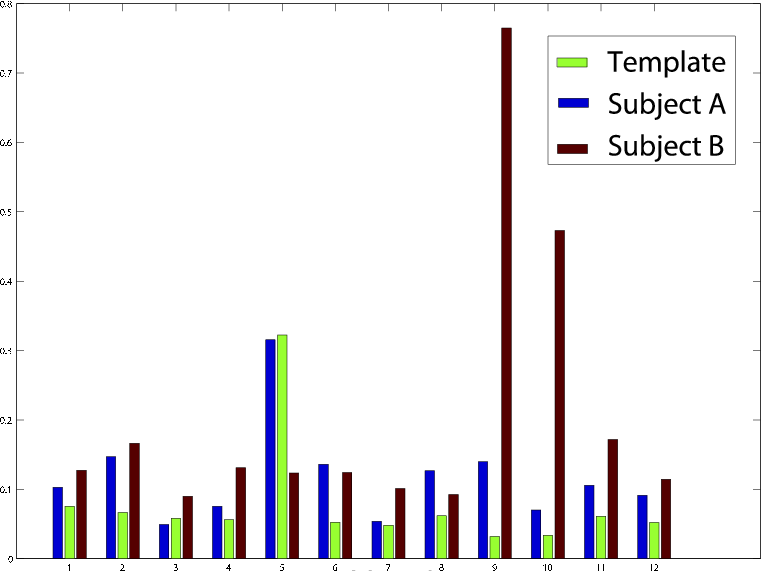
When we ran our experiments we found that while the template speaker was occasionally not the person with the lowest percent error on a per-vowel basis he had the lowest percent error across the entire vowel space. We found this result to be consistent across several different trials. In each a trial a new recording of the same three people was made - often on different days, in order to allow for maximum day to day variability in voice and recording positioning. We wanted to make sure that it was not just a particular set of data that looked good against the template speaker. In addition we wanted the template speaker to make several recordings to ensure that the system could cope with differences in both the template speaker and in the potential intruders.
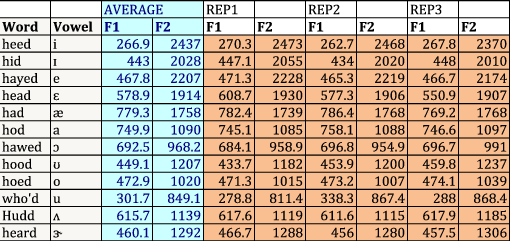
| Subject | Average % Error Trial 1 | Average % Error Trial 2 | Average % Error Trial 3 |
| Template Speaker | 7.673 | 8.902 | 7.747 |
| Speaker A | 11.787 | 11.301 | 11.102 |
| Speaker B | 20.676 | 16.933 | 12.389 |
More detail on each of the trials can be found in Figures [link] , [link] , [link]
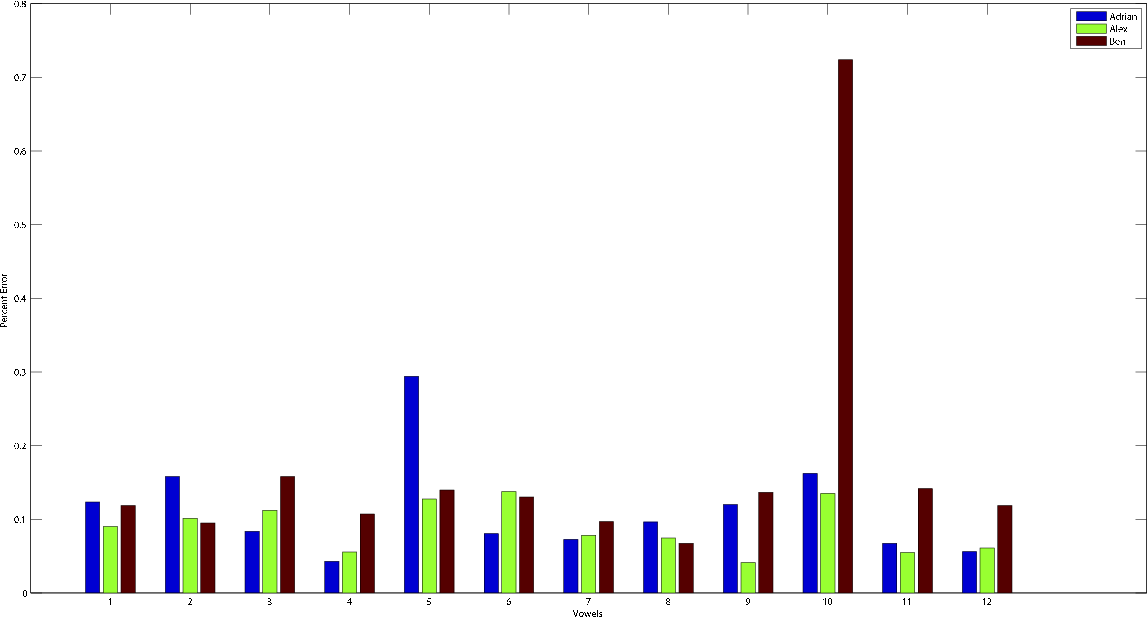

In conclusion we found that the system we built does exactly as we intended: it is able to tell the difference between the user it was tuned to and everybody else. There were a few caveats to the system we built. In particular we noticed that when the template speaker got a little sick the system was no longer able to grant him access. Due to the newfound resonant characteristics of the template speaker's vocal tract caused no doubt by the addition of mucous and swelling, it was quite difficult for the system to match it to the stored template formants.This is a bit of a sticky problem because we want to tune the system as sharply as we can to the template speaker's resonant characteristics so that even a slight change would cause the system to revoke the user. These slight changes seen through a security lens are an added opportunity to take advantage of the entire variability space to increase "passphrase" entropy and make the entire system more secure. The same slight changes seen through a usability perspective however are seen as a rather formidable annoyance for the sick template user attempting to gain access to his environment. This balance between lenience and security is one that most biometric security systems must weigh. Anyone who has attempted to use a fingerprint reader after a long shower (raisined fingers) knows which way the company that made that biometric system choose to lean towards. In the same manner we figured that while the balance could definitely use some fine tuning we figured it would be best to produce a false negative than to produce a false positive and allow a rouge user access to the secure environment. Of interesting note we noticed that when a user changed the pitch of his voice in order to try to match the template speaker the position of the formants in the frequency domain changed very little. This result shows that the system is indeed tuned to a user's resonant characteristics and not just the pitch of the voice. This result also makes it extremely difficult for a would be attacker to gain access to the system even if he did know the exact passphrase and what the secured template user sounds like.
In its current state the formant detection system makes use of several very convenient MATLAB features such as the filter design tool to rapidly create a computable filter. It also leverages the rather large amount of computational power available to modern computer platforms to make some rather sharp filters and decisions. While it is true that we did not set out to make the most efficient mechanism by which to identify a user based on formants, we would truly like to see this system implemented in an embedded hardware environment. This would require that we trim the program and its requisite filters considerably just to get the algorithm to fit within the confines of the restricted memory space available in most embedded environments. In addition this type of embedded security system is of little use if it cannot be run at real or near-real time speeds. Use of a powerful embedded environment such as an FPGA could see this type of implementation without a drastic reduction in the filter sharpness; however such an implementation would also require considerable effort in order to port the filter and surrounding decision rules into the hardware reconfigurable languages of Verilog or VHDL.
In order to accurately guess whether the right vowel is even being spoken before attempting to compute a percent error from a potentially wrong vowel to the template speaker we had to build in some sort of vowel recognition feature. The recognition implementation is rather crude but we found it to be quite accurate in our tests. We never tested the vowel recognition alone but rather saw the results of it in the streaming debug statements our program can output. Based solely on this we believe that the subsystem could be expanded and refined to both aide in the voice recognition process and to increase security by fully checking the phrase spoken.
Notification Switch
Would you like to follow the 'Voice recognition' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|