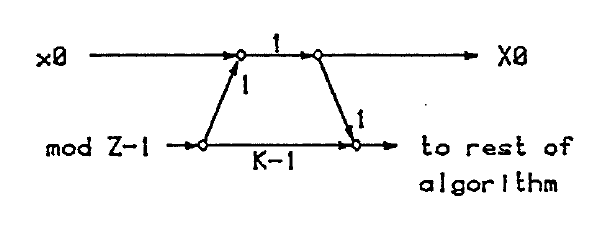
Now, suppose we combine length p and q modules with Good's prime factor algorithm (not using twiddles). The following scaling procedure will work:
Assume the input data has been appropriately loaded into a
data array
Scale the non-DC outputs of the length
module and apply the modified module to all columns of the data array.
Now all the rows are scaled by
except the zeroeth row, corresponding to the DC outputs of the length
modules. Apply a normal length
module to the zeroeth row. Modify the length
module to scale by
and apply the modified version to all the other rows. The DFT is now complete.
As an example, consider the 3x7 DFT. In the length 3 module scaling the non-DC outputs trades one multiply for one add. When the scaled DFT is constructed, the modified length 3 module is used 7 times. But two rows must be scaled by modified length 7 modules, which brings the total multiply savings to 5 at a cost of 7 adds. This looks like a nice tradeoff. The total number of multiplies in a normal 3x7 PFA is 38.
These ideas can be expanded to multidimensional cases, although it quickly becomes difficult to keep track of which rows and columns need to be counter-scaled.
Use the index map
to convert the DFT into a length 10 convolution, plus a correction term for the DC components.
Reduce the length 10 convolution modulo all the irreducible factors of
from
data
from
data
Patch up the DC terms by adding the
reduction result to
and store the result in AMO.
The
convolution proceeds in four steps. First, do the irreducible factor reductions, then reduce further with an iterated Toom-Cook procedure, weight all remaining variables, and apply the transpose of the complete reduction stage to the weighted results. The first Toom-Cook reduction uses the factors
,
and
on the vectors AM4,AM3 and AM7,AM6 which generates the new vector AM4-AM7,AM3-AM6. Each of the original two vectors is then individually reduced using factors of
,
and
, while the new vector is reduced by
,
and
. This procedure generates nine variables: AM4,AM3,AM5; AM7,AM6,AM8; S7,S8,AM11. (The expressions for S6 and S8 contain the variables of interest).
The nine variables from 4) are weighted along with T13.
An exact transpose of the reduction algorithm is applied to the weighted variables (and AMO).
The result S16,S15,S18,S17,S19 is the real part of the answer and is mapped back to the output using the map
. This is an unusual map, but it is perfectly acceptable.
A in the length 19 transform the
convolution is computed with a variation of the
algorithm. First the inputs T6,-T8,-T7,-T1O,T9 are alternately negated, then the
algorithm is applied
The second stage of the Toom-Cook reductions uses the factors z, liz and z+l for all three length two vectors. Also, the DC patch is not used here. and the outputs alternately negated.
The result S21,S20,S23,S22,S24, representing the imaginary part of the answer, is mapped back to the output using the map
.
In both this algorithm and the length 13 DFT plus and minus signs have been freely altered to force all constants to be positive. Also, many shortcut computations were used to save adds, obscuring in some places the logical flow of the algorithm.
All coefficients were computed using the author's QR decomposition linear equation solver and are accurate to at least 14 places.
Length 13 module: 188 adds / 40 mpys
Use the index map
to convert the DFT into a length 12 convolution, plus a correction term for the DC components.
Reduce the length 12 convolution modulo all the irreducible factors of
from
data
from
data
from
data
Patch up the DC terms by adding the
reduction result to
and store the result in AMO.
The
and
convolutions are reduced using Toom-cook factors of
,
and
in one case and
,
and
in the other case, and then all the reduced quantities are weighted by constants generating new variables:
from
from
The original
reduction quantity is weighted and passed, along with AMO and the above six variables, to a reconstruction procedure which first combines the
and
data to compute the convolution mod
(CC4,CC5,CC6), and then combines the
and
data to compute the convolution mod
(CC1,CC2,CC3). These two vectors are combined to compute the complete
output, which appears in permuted form in CC15 through CC20.
The
vector is decomposed with Toom-Cook factors of
,
and
yielding A17,A16 and the implicit term (A16+A17).
The
vector is decomposed with a double iterated Toom-Cook scheme. First the vector is broken into two length two pieces: A27,A26 and A31,A30. Then the vectors are reduced by the factors of
,
and
operating on whole vectors to produce a set of three length two vectors:
Ā27,A26A31,A30
A29,A28 = (A27+A31), (A26+A30)These vectors are not calculated in a straightforward manner. Each length two vector is further reduced, in the second iteration, by the factors
,
and
to create three new implicit variables
,
and
.
The nine variables from
[link] and the three variables from
[link] are weighted by constants and the
reconstruction proceeds in an ad-hoc fashion which closely resembles a transposed tensor method, but has some differences. The add count for the reconstruction would have been the same if the transposed tensor method had been applied. The
result appears in permuted form in variables CC21 through CC26.
The final result is reconstructed from the
and
vectors. The DC term,
is set equal' to AMO.
All coefficients were computed using the author's QR decomposition linear
equation solver and are accurate to at least 14 places.
Receive real-time job alerts and never miss the right job again
Source:
OpenStax, Large dft modules: 11, 13, 16, 17, 19, and 25. revised ece technical report 8105. OpenStax CNX. Sep 14, 2009 Download for free at http://cnx.org/content/col10569/1.7
Google Play and the Google Play logo are trademarks of Google Inc.
Notification Switch
Would you like to follow the 'Large dft modules: 11, 13, 16, 17, 19, and 25. revised ece technical report 8105' conversation and receive update notifications?