

| << Chapter < Page | Chapter >> Page > |
(From Wikipedia, the free encyclopedia)
In cryptography, hash trees (also known as Merkle trees) are an extension of the simpler concept hash list , which in turn is an extension of the old concept of hashing.
Uses
Hash trees can be used to protect any kind of data stored, handled and transferred in and between computers. Currently the main use of hash trees is to make sure that data blocks received from other peers in a peer-to-peer network are received undamaged and unaltered, and even to check that the other peers do not lie and send fake blocks. Suggestions have been made to use hash trees in trusted computing systems.
How hash trees work
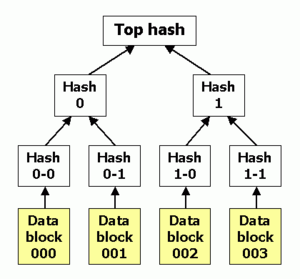
A hash tree is a tree of hashes in which the leaves are hashes of data blocks in, for instance, a file or set of files. Nodes further up in the tree are the hashes of their respective children. For example, in the picture hash 0 is the result of hashing hash 0-0 and then hash 0-1. That is, hash 0 = hash( hash 0-0 | hash 0-1 ).
Most hash tree implementations are binary (two child nodes under each node) but they can just as well use many more child nodes under each node.
Usually, a cryptographic hash function such as SHA-1, Whirlpool, or Tiger is used for the hashing. If the hash tree only needs to protect against unintentional damage, the much less secure checksums such as CRCs can be used.
In the top of a hash tree there is a top hash (or root hash or master hash). Before downloading a file on a p2p network, in most cases the top hash is acquired from a trusted source, for instance a friend or a web site that is known to have good recommendations of files to download. When the top hash is available, the hash tree can be received from any non-trusted source, like any peer in the p2p network. Then, the received hash tree is checked against the trusted top hash, and if the hash tree is damaged or fake, another hash tree from another source will be tried until the program finds one that matches the top hash.
The main difference from a hash list is that one branch of the hash tree can be downloaded at a time and the integrity of each branch can be checked immediately, even though the whole tree is not available yet. This can be an advantage since it is efficient to split files up in very small data blocks so that only small blocks have to be redownloaded if they get damaged. If the hashed file is very big, such a hash tree or hash list becomes fairly big. But if it is a tree, one small branch can be downloaded quickly, the integrity of the branch can be checked, and then the downloading of data blocks can start.
There are several additional tricks, benefits and details regarding hash trees. See the references and external links below for more in-depth information.
(From Wikipedia, the free encyclopedia)
A hash function is a reproducible method of turning some kind of data into a (relatively) small number that may serve as a digital "fingerprint" of the data. The algorithm "chops and mixes" (i.e., substitutes or transposes) the data to create such fingerprints. The fingerprints are called hash sums, hash values, hash codes or simply hashes. (Note that hashes can also mean the hash functions.) Hash sums are commonly used as indices into hash tables or hash files. Cryptographic hash functions are used for various purposes in information security applications.
Notification Switch
Would you like to follow the 'Data structures and algorithms' conversation and receive update notifications?

|
|

|
|

|
|

|
|

|
|

|
|

|
|
|
|
|

|
|

|